Organisation auswählen
Fehlerbehebung bei Netzwerkleistungsproblemen mit 'ping' und 'traceroute'
Veröffentlichungsdatum: Sep 13, 2022
Beschreibung
Wenn die Verbindung zu Salesforce langsam ist oder eine hohe Latenz besteht, sollten Sie diesen Artikel lesen. Darin erfahren Sie, wie Sie Ping- und Traceroute-Befehle ausführen können, um den Ursprung der langsamen Anwendungsausführung zu isolieren. Salesforce bittet Sie bei der Behebung von Leistungsproblemen, bei denen das Netzwerk als Ursache vermutet wird, einen Traceroute-Befehl auszuführen und die Protokolle entsprechend freizugeben.
Lösung
Anfängliche Fehlerbehebung:
Wenn die Verbindung zu Salesforce langsam ist oder eine hohe Latenz besteht, sollten Sie diesen Artikel lesen. Darin erfahren Sie, wie Sie einen Ping- und Traceroute-Befehle ausführen können, um den Ursprung der langsamen Anwendungsausführung zu ermitteln. Vor der Fehlerbehebung von Netzwerkproblemen sollten Sie einige Bereiche überprüfen, um sicherzustellen, dass es sich nicht um ein bekanntes Problem handelt, dessen Lösung bereits in Arbeit ist.
1. Überprüfen Sie Trust.
In solchen Fällen sollten Sie immer zunächst status.salesforce.com/status konsultieren. Auf der Salesforce-Seite für den Trust-Status werden fortlaufende Vorfälle und Wartungsaktivitäten gemeldet, die sich auf Ihre Instanz auswirken können. Zusätzlich zur Salesforce-Aktivität werden gelegentlich allgemeine Statusmeldungen gepostet, wenn mit einem ISP zusammengearbeitet wird, um Netzwerkprobleme zu lösen.
2. Fragen Sie Ihre Kollegen.
Prüfen Sie, ob Ihr gesamtes Team ebenfalls auf demselben Leistungsniveau arbeitet und ob es Problemlinderungen gibt, beispielsweise wenn Sie immer eine Festnetzverbindung verwenden, aber einen Kollegen haben, der WLAN verwendet, das Problem jedoch nicht hat. Wenn Ihr Unternehmen mehrere Standorte oder Remote-Mitarbeiter besitzt, sollten Sie ebenfalls entsprechend nachfassen, ob dort ihre Leistung besser ist. Stellt Ihr Team dieselbe Leistung in allen Ihren Organisationen fest (einschließlich Sandbox-Instanzen)? Wenn eines dieser Szenarien auf dieses Problem zutrifft, dann liegt mit großer Wahrscheinlichkeit ein Netzwerkproblem, aber kein Salesforce-spezifisches Problem vor.
Ausführen von Traceroute- und Ping-Befehlen unter Microsoft Windows
1. Klicken Sie auf der Windows-Taskleiste auf die Schaltfläche Start und wählen Sie Ausführen aus.
2. Geben Sie den Befehl cmd in das Textfeld ein.
3. Klicken Sie auf OK. Ein DOS-Fenster wird angezeigt.
4. Geben Sie im DOS-Fenster Folgendes ein und drücken Sie die EINGABETASTE.
tracert login.salesforce.com >> c:\tracert.txt
5. Geben Sie zum Senden von 100 Echo-/Ping-Anforderungen Folgendes ein und drücken Sie die EINGABETASTE:
ping -n 100 login.salesforce.com >> c:\ping.txt
6. Wiederholen Sie die Schritte 4 und 5 und ersetzen Sie dabei den URL durch Ihre Instanz. Beispiel:
tracert na1.salesforce.com >> c:\tracert.txt
ping na1.salesforce.com >> c:\ping.txt
Da der Windows-Befehl "tracert" nur einen einzelnen Snapshot des Netzwerks zu einem bestimmten Zeitpunkt abbildet, sollten Sie den Befehl mehrfach ausführen, damit eine aussagekräftige Datenprobe gesammelt wird. Navigieren Sie nach Abschluss dieses Prozesses auf Laufwerk C:\ zu den Ausgabedateien. Wenn ein fortlaufender Kundenvorgang mit Ihrem internen Netzwerkteam oder mit dem Salesforce-Support vorliegt, können Sie in diesen Protokollen die Ursache eines potenziellen Netzwerkproblems identifizieren.
Bei der Kommunikation mit Ihrem Computer überträgt Salesforce unterschiedlich große Pakete. Wenn Sie die grundlegenden Traceroute- und Ping-Befehle erfolgreich an salesforce.com gesendet haben, wie oben beschrieben, sollten Sie diesen Anweisungen folgen, um umfangreichere Paketübertragungstests auszuführen.
1. Klicken Sie auf der Windows-Taskleiste auf die Schaltfläche Start und wählen Sie Ausführen aus.
2. Geben Sie den Befehl cmd in das Textfeld ein.
3. Klicken Sie auf OK. Ein DOS-Fenster wird angezeigt.
4. Geben Sie im DOS-Fenster jeweils einen der folgenden Befehle ein und drücken Sie die EINGABETASTE.
2. Geben Sie den Befehl cmd in das Textfeld ein.
3. Klicken Sie auf OK. Ein DOS-Fenster wird angezeigt.
4. Geben Sie im DOS-Fenster jeweils einen der folgenden Befehle ein und drücken Sie die EINGABETASTE.
Hinweis: Warten Sie, bis die einzelnen Befehle vollständig ausgeführt wurden, bevor Sie den nächsten Befehl eingeben. In allen Schritten ist das Zeichen vor 1200, 1300 und 1400 ein kleingeschriebenes "Bindestrich-L".
ping -f -n 25 -l 1200 login.salesforce.com >>C:\sfdcping.txt
ping -f -n 25 -l 1300 login.salesforce.com >>C:\sfdcping.txt
ping -n 25 -l 1400 login.salesforce.com >>C:\sfdcping.txt
5. Wiederholen Sie Schritt 5 und ersetzen Sie dabei den URL durch Ihre Instanz. Beispiel:
ping -f -n 25 -l 1200 na1.salesforce.com >> C:\sfdcping.txt
ping -f -n 25 -l 1300 na1.salesforce.com >>C:\sfdcping.txt
ping -n 25 -l 1400 na1.salesforce.com >>C:\sfdcping.txt
Navigieren Sie auf Ihrem Laufwerk "C:\" zur Ausgabedatei "sfdcping.txt".
Ausführen von Traceroute- und Ping-Befehlen auf macOS
macOS von Apple enthält eine Traceroute-Funktion, auf die über die Befehlszeile mit der Terminal-Anwendung und über die GUI mit dem "Netzwerkdienstprogramm" zugegriffen werden kann, das in jeder macOS-Version enthalten ist.
Traceroute mit "Terminal.app"
1. Öffnen Sie eine Terminal-Sitzung mit "Terminal.app".
2. Führen Sie die folgenden Traceroute-Befehle aus:
2. Führen Sie die folgenden Traceroute-Befehle aus:
traceroute login.salesforce.com
traceroute ihreinstanz.salesforce.com
3. Kopieren Sie die Ergebnisse und fügen Sie sie in einen Texteditor oder eine Antwort-E-Mail ein.
Traceroute mit dem Netzwerkdienstprogramm
1. Öffnen Sie "Network Utility.app" im Ordner "Utilities".
2. Klicken Sie auf Traceroute.
3. Geben Sie zunächst "login.salesforce.com" und dann ihreinstanz.salesforce.com ein.
4. Klicken Sie auf Trace.
5. Kopieren Sie die Ergebnisse und fügen Sie sie in einen Texteditor oder eine Antwort-E-Mail ein.
2. Klicken Sie auf Traceroute.
3. Geben Sie zunächst "login.salesforce.com" und dann ihreinstanz.salesforce.com ein.
4. Klicken Sie auf Trace.
5. Kopieren Sie die Ergebnisse und fügen Sie sie in einen Texteditor oder eine Antwort-E-Mail ein.
Hinweis: Führen Sie die obigen Schritte aus, um einen Traceroute-Befehl an Ihren Live Agent-Server zu senden. Verweisen Sie dabei aber nicht auf den URL der Salesforce-Instanz, sondern auf Ihren Live Agent-Server. Navigieren Sie zum Aufrufen Ihres Live Agent-Servers zu "Setup" und geben Sie im Feld "Schnellsuche" den Text "Live Agent-Einstellungen" ein. Es wird ein Endpunkt-URL angezeigt, der "https://d.la1w1.salesforceliveagent.com/chat/rest/" ähnelt. Entfernen Sie "https://" und "/chat/rest/". Führen Sie den Traceroute-Befehl dann lediglich für den Teil der Adresse "d.la1w1.salesforceliveagent.com" aus.
Interpretieren der Ping-Ergebnisse
Die Ausgabe eines Ping-Befehls ähnelt dem folgenden Ping-Befehl, der an "na17.salesforce.com" gesendet wird.

Die obigen Ergebnisse weisen auf eine schnelle Verbindung ohne Paketverluste hin. Anzeichen für ein Problem wären unter anderem:
- Paketverlust von mindestens 10 %. Im obigen Beispiel lag der Verlust bei 0 %.
- Eine Diskrepanz zwischen den minimalen, maximalen und durchschnittlichen Roundtripzeiten. Im obigen Beispiel lautet die minimale Roundtripzeit 104 ms, die maximale 107 ms und die durchschnittliche 104 ms. Diese Ergebnisse deuten darauf hin, dass in einem bestimmten Zeitraum, in dem Ping-Befehle erfasst wurden, eine geringfügige Latenzabweichung bestand. Läge der minimale bei 100 ms und der maximale Wert bei 500 ms in den Ergebnissen, würde dies jedoch auf Latenzprobleme hindeuten, die zeitweise eine verschlechterte Verbindung verursachen würden.
Interpretieren von Traceroute-Ergebnissen
Eine Traceroute zeigt Leistungsstatistiken für jeden Hop auf dem Netzwerkpfad, der von Ihrem Computer durchlaufen wird, um Salesforce zu erreichen, um herauszufinden, wo möglicherweise Probleme auftreten.
Traceroute-Terminologie
- Hop-Nummer: Die spezifische Hop-Nummer auf dem Pfad vom Absender zum Ziel.
- Roundtripzeit: Gibt in Millisekunden (ms) an, wie lange ein Paket benötigt, um zu einem Hop und zurück zu gelangen. Standardmäßig sendet "tracert" drei Pakete an jeden Hop. Daher werden in der Ausgabe drei Roundtripzeiten pro Hop aufgelistet. Die Roundtripzeit wird auch als Latenz bezeichnet. Ein wichtiger Faktor, der sich auf die Roundtripzeit auswirken kann, ist die physische Distanz zwischen den Hops. Eine ausführliche Beschreibung der Roundtripzeit und der zugehörigen Auswirkungen finden Sie im Artikel Auswirkungen der Roundtripzeit und Bandbreite auf die Leistung.
- Name: Der vollqualifizierte Domänenname des Systems. Oft gibt der vollqualifizierte Domänenname an, wo sich der Hop physisch befindet. Wird der Name in der Ausgabe nicht angezeigt, wurde der vollqualifizierte Domänenname nicht gefunden. Wird ein vollqualifizierter Domänenname nicht gefunden, deutet dies nicht zwangsläufig auf ein Problem hin.
- IP-Adresse: Die Internetprotokolladresse (IP) dieses spezifischen Routers oder Hosts, der dem Namen zugeordnet ist.
Die Komponenten einer Traceroute
Im Folgenden finden Sie eine Traceroute zur nordamerikanischen Salesforce-Instanz NA17 (tracert na17.salesforce.com):

In der ersten Zeile der tracert-Ausgabe wird beschrieben, was der Befehl umsetzt. Darin werden das Zielsystem (salesforce.com), die IP-Zieladresse und die maximale Anzahl der Hops aufgelistet, die in der Traceroute (30) verwendet werden.
Der erste Hop ist der anfängliche Haltepunkt Ihres Datenverkehrs nach dem Verlassen Ihres Computers. Hierbei handelt es sich wahrscheinlich um eine 10.X.X.X- oder 192.168.X.X-Nummer. Diese sind für private Netzwerke reserviert und auch weiter unten in einer Traceroute recht häufig anzutreffen. Frühe Hops auf der Route mit diesen Adressenpräfixen befinden sich in der Regel im internen Netzwerk Ihres Unternehmens. Weiter unten auf der Route geben sie einfach an, dass der Datenverkehr vor dem Verlassen das interne Netzwerk des ISPs durchläuft.
Identifizieren allgemeiner Probleme
Die 3 angezeigten Nummern sind die einzelnen Zeiten, um zu diesem spezifischen Hop zu gelangen. Es ist wichtig darauf hinzuweisen, dass diese Nummern nicht den Zeitunterschied zwischen dem aktuellen und dem vorherigen Hop darstellen, sondern die kumulative Zeit bis zu diesem Hop. Wenn Sie sich eine Traceroute ansehen, suchen Sie nach dem ersten Punkt, an dem es eine hohe Variation zwischen den Zeiten (beispielsweise: 50 ms, 283 ms, 29 ms) gibt oder nach Zeiten, die durchweg viel höher sind als die des vorhergehenden Hops. Möglicherweise wird auch "*" als Eintrag angezeigt. Dieser gibt an, dass vom Server keine Antwort empfangen wurde. Dies deutet nicht zwangsläufig auf ein Problem hin, insbesondere sobald Sie auf Salesforce zugreifen. Bestimmte Netzwerke antworten aus Sicherheits- oder Priorisierungsgründen nicht auf die in Traceroutes verwendeten Pakete. Sobald Sie sich im Rechenzentrum befinden, geht Salesforce auf die gleiche Weise vor. Wenn Sie eine Zeitüberschreitung bei einem Hop feststellen, ist dies wahrscheinlich kein Problem, sofern die Verbindung konsistent bestehen bleibt. Beachten Sie, dass Ihre "normalen" Traceroute- und Ping-Ergebnisse basierend auf dem geografischen Standort Ihres Systems und des Rechenzentrums variieren werden. Wenn Sie sich beispielsweise in Australien befinden und Sie eine Verbindung zu einem Rechenzentrum herstellen, dass sich im Osten der USA befindet, ist eine Roundtripzeit von 250–300 ms nicht ungewöhnlich aufgrund der geografischen Distanz, welche die Verbindung physisch in Unterseekabeln durchlaufen muss. Dagegen ist eine Roundtripzeit von 300 ms ungewöhnlich, wenn zwischen dem Rechenzentrum in Australien und Tokio eine Verbindung hergestellt wird.
Traceroute-Ergebnisse, die eine erhöhte Latenz bei einem mittleren Hop zeigen, die bis zum Ziel ähnlich bleibt, deuten nicht auf ein Netzwerkproblem hin. Eine Traceroute, die bei einem mittleren Hop eine erheblich erhöhte Latenz zeigt, die dann bis zum Ziel stetig zunimmt, kann auf ein potenzielles Netzwerkproblem hinweisen. Paketverluste oder Sternchen (*) auf vielen der mittleren Hops können auf ein mögliches Netzwerkproblem hinweisen, wenn das Ziel nicht erreichbar ist oder die Latenzzeit in nachfolgenden Hops erheblich ansteigt. Ein stetiger Trend zunehmender Latenzzeiten ist in der Regel ein Anzeichen auf eine Überlastung oder ein Problem zwischen zwei Punkten im Netzwerk und es erfordert eine oder mehrere Parteien, das Problem zu beheben.
Weitere Details zum Interpretieren von Traceroutes finden Sie in dieser PDF-Datei:
https://major.io/wp-content/uploads/2012/06/RAS_Traceroute_NANOG_slides.pdf
Sternchen oder Meldungen vom Typ "Zeitüberschreitung bei Anforderung"
Wenn für eine Roundtripzeit ein Sternchen (*) angezeigt wird, wurde ein Paket nicht im erwarteten Zeitrahmen zurückgegeben. Ein oder zwei Sternchen für einen Hop deuten nicht zwangsläufig auf einen Paketverlust am Zielort hin.
Werden drei Sternchen angezeigt, wird für mindestens einen Hop auf dem Pfad die Meldung "Zeitüberschreitung bei Anforderung" angezeigt. Dies deutet nicht zwangsläufig auf ein Netzwerk- oder ISP-Problem hin. Meistens bedeutet dies, dass diese Hops ICMP-Pakete (Ping- und Traceroute) nicht priorisieren. Im Folgenden finden Sie ein Beispiel dazu:
Da das Ziel erreicht werden konnte, deutet dies darauf hin, dass bei den mittleren Hops keine Verluste bei der Weiterleitung auftraten. Zudem lässt das konsistente und niedrige Latenzniveau am Verbindungsende den Schluss zu, dass keine Netzwerkprobleme vorliegen.
Aus den folgenden Gründen werden möglicherweise drei Sternchen, gefolgt von "Zeitüberschreitung bei Anforderung" angezeigt:
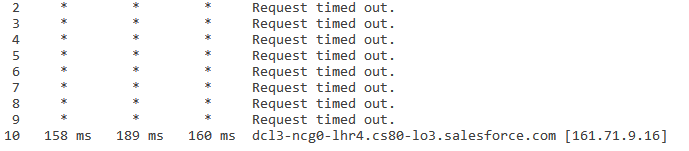
- ICMP-Paket-Entpriorisierung.
- Die Firewall des Ziels oder ein anderes Sicherheitsgerät blockiert die Anforderung.
- Es könnte ein Problem auf dem Rücksendepfad vom Zielsystem geben. Beachten Sie, dass mit der Roundtripzeit gemessen wird, wie lange ein Paket benötigt, um von Ihrem System an ein Zielsystem und zurück gesendet zu werden. Die Vorwärts- und Rückwärtsroute folgen oft unterschiedlichen Pfaden. Liegt ein Problem auf der Rückwärtsroute vor, ist dies in der Befehlsausgabe möglicherweise nicht ersichtlich.
- Möglicherweise liegt ein Verbindungsproblem dieses bestimmten oder des nächsten Systems vor.
Seltsame Weiterleitungsentscheidungen
ISPs nehmen fortlaufend Aktualisierungen an ihren Netzwerken vor, beispielsweise passen sie Weiterleitungsentscheidungen an und fügen neue Leitungen hinzu, um die Integrität ihres Netzwerks aufrechtzuerhalten und um bestimmte Datenverkehrsmuster zu optimieren. Diese Änderungen können gelegentlich dazu führen, dass Ihre Anforderungen über einen nicht so optimalen Pfad an Salesforce geleitet werden. So werden Sie beispielsweise sicherlich erhöhte Ladezeiten feststellen, wenn Sie von Kalifornien aus auf eine Salesforce-Instanz in Nordamerika zugreifen, aber über Singapur und zurück geleitet werden, bevor Sie die Anwendung erreichen. Sie können diese Weiterleitungsprobleme in der Traceroute identifizieren. Überprüfen Sie dazu die Namen der Hops, die von ISPs tendenziell mit standortbasierten Informationen versehen werden, und ob ein Spitzenwert der Roundtripzeit von 100–200 ms über die Spanne von 1 Hop vorliegt, was ein typisches Verhalten eines interkontinentalen Hops darstellt.Wenn Sie in derselben Region wie Ihr Rechenzentrum (Nordamerika für NAXX-Instanzen, Asien für APXX, Europa/Afrika für EUXX) ansässig sind und Sie einen großen Anstieg in Ihren Traceroutes feststellen, können Sie [IP-Adresse].ipaddress.com aufrufen, um den geografischen Standort der spezifischen IP-Adresse zu ermitteln, wo der Anstieg erfolgt. Wenn Sie diese Art von Problem feststellen, wenden Sie sich an Ihren ISP, da er die Route steuert, die Ihre Anforderung bis Salesforce durchläuft.
Kontaktieren des Salesforce-Supports
Wenn Sie keine Netzwerkprobleme ausmachen können, senden Sie alle gesammelten Informationen unter Beachtung der obigen Schritte an den Salesforce-Support. Dann sieht sich Salesforce das Problem genauer an. Zusätzlich zum oben beschriebenen Traceroute- und Ping-Befehl sollten Sie die Anmeldezugriffsdaten, die Reproduzierungsschritte der festgestellten Langsamkeit und den Namen Ihres Internetserviceanbieters (Internet Service Provider, ISP) bereitstellen und angeben, ob Ihr ISP einen Einblick in die Latenzzeit gewährt hat.
Nummer des Knowledge-Artikels
000385480
Konnten Sie Ihr Problem mithilfe dieses Artikels lösen?
Geben Sie uns Feedback, damit wir uns verbessern können.