Seleccionar una organización
Resolver problemas de rendimiento de red con ping y traceroute
Fecha de publicación: Sep 13, 2022
Descripción
Si está intentando conectar con Salesforce y tiene problemas con la lentitud o la latencia, este artículo le mostrará como ejecutar un comando ping y traceroute para aislar el origen de la lentitud de las aplicaciones. Salesforce le solicitará que ejecute un traceroute y que comparta los registros con nosotros cuando estemos solucionando problemas de rendimiento cuando se sospeche que la causa es la red.
Solución
Solución inicial de problemas:
Si está intentando conectar con Salesforce y tiene problemas con la lentitud o la latencia, este artículo le mostrará como ejecutar un comando ping y traceroute para aislar el origen de la lentitud de las aplicaciones. Antes de solucionar problemas de red, recomendamos comprobar algunas áreas para garantizar que no es un problema conocido con una solución ya en curso.
1. Consultar Trust
Lo primero que hay que hacer siempre en estos casos es consultar status.salesforce.com/status. La página Estado de Salesforce en Trust informará de cualquier incidente que se esté produciendo y la actividad de mantenimiento que podría estar afectando a su instancia. Además de la actividad de Salesforce, también publicamos ocasionalmente mensajes de estado generales si estamos realizando con un ISP pruebas para solucionar problemas de red.
2. Preguntar a sus compañeros.
Compruebe si todo su equipo está sufriendo también el mismo nivel de rendimiento y si han encontrado formas de mitigarlo. Por ejemplo, usted siempre utiliza una conexión cableada, pero tiene un compañero que utiliza WiFi y no está sufriendo el problema. Del mismo modo, si su empresa tiene varias oficinas o empleados remotos, consúlteles si tienen un mejor rendimiento. ¿Tiene su equipo el mismo nivel de rendimiento en todas sus organizaciones (incluyendo sandboxes)? Si cualquiera de estos escenarios son aplicables al problema, entonces lo más probable es que esté sufriendo un problema de red y no un problema específico de Salesforce.
Ejecución de los comandos Traceroute y Ping en Microsoft Windows
1. En la barra de tareas de Windows, haga clic en el botón Inicio | seleccione Ejecutar.
2. Escriba cmd en el cuadro de texto.
3. Haga clic en Aceptar. Aparecerá una ventana DOS.
4. En la ventana DOS, escriba lo siguiente y pulse Entrar:
tracert login.salesforce.com >> c:\tracert.txt
5. Para enviar 100 solicitudes ping de eco, escriba lo siguiente y pulse Entrar:
ping -n 100 login.salesforce.com >> c:\ping.txt
6. Repita los pasos 4 y 5 sustituyendo la URL con su instancia. Por ejemplo:
tracert na1.salesforce.com >> c:\tracert.txt
ping na1.salesforce.com >> c:\ping.txt
Ya que el comando tracert de Windows es solo una única instantánea de la red en un punto en el tiempo, recomendamos ejecutar el comando muchas veces para garantizar un buen muestreo de los datos que recopila. Después de completar este proceso, navegue a su unidad C:\ para encontrar los archivos de resultados. Si tiene un caso continuo con su equipo de red interno o el Servicio de atención al cliente de Salesforce, estos registros ayudarán a identificar el origen de un posible problema de red.
Salesforce transmite paquetes de diversos tamaños cuando se comunica con su equipo. Si ha ejecutado comandos tracert y ping básicos correctamente a salesforce.com como se indica anteriormente, siga estas instrucciones para realizar más pruebas de transmisión de paquetes extensivas.
1. En la barra de tareas de Windows, haga clic en el botón Inicio | seleccione Ejecutar.
2. Escriba cmd en el cuadro de texto.
3. Haga clic en Aceptar. Aparecerá una ventana DOS.
4. En la ventana DOS, escriba cada uno de los siguiente pasos, uno por uno y pulse Entrar.
2. Escriba cmd en el cuadro de texto.
3. Haga clic en Aceptar. Aparecerá una ventana DOS.
4. En la ventana DOS, escriba cada uno de los siguiente pasos, uno por uno y pulse Entrar.
Nota: Permita que cada comando se procese completamente antes de introducir el siguiente comando. En todos los pasos, el carácter antes de 1200, 1300 y 1400 is es un"guión L" en minúsculas.
ping -f -n 25 -l 1200 login.salesforce.com >>C:\sfdcping.txt
ping -f -n 25 -l 1300 login.salesforce.com >>C:\sfdcping.txt
ping -n 25 -l 1400 login.salesforce.com >>C:\sfdcping.txt
5. Repita el paso 5 sustituyendo la URL con su instancia. Por ejemplo:
ping -f -n 25 -l 1200 na1.salesforce.com >> C:\sfdcping.txt
ping -f -n 25 -l 1300 na1.salesforce.com >>C:\sfdcping.txt
ping -n 25 -l 1400 na1.salesforce.com >>C:\sfdcping.txt
Navegue a su unidad C:\ para encontrar el archivo de resultados sfdcping.txt.
Ejecución de los comandos Traceroute y Ping en macOS
macOS de Apple viene con una función traceroute a la que se puede tener acceso a través de la línea de comandos empleando la aplicación Terminal y la interfaz gráfica de usuario con la aplicación Utilidad de red que viene con todas las versiones de macOS.
Traceroute empleando Terminal.app
1. Abra una sesión de terminal empleando Terminal.app.
2. Ejecute estos comandos traceroute:
2. Ejecute estos comandos traceroute:
traceroute login.salesforce.com
traceroute suinstancia.salesforce.com
3. Copie y pegue los resultados en un editor de texto o correo electrónico de respuesta.
Traceroute empleando la Utilidad de red
1. Abra Utilidad de red.app, ubicada en la carpeta Utilidades.
2. Haga clic en Traceroute.
3. Introduzca login.salesforce.com la primera vez y suinstancia.salesforce.com la segunda vez.
4. Haga clic en Rastrear.
5. Copie y pegue los resultados en un editor de texto o correo electrónico de respuesta.
2. Haga clic en Traceroute.
3. Introduzca login.salesforce.com la primera vez y suinstancia.salesforce.com la segunda vez.
4. Haga clic en Rastrear.
5. Copie y pegue los resultados en un editor de texto o correo electrónico de respuesta.
Nota: Para ejecutar un comando traceroute a su servidor de Live Agent, realice los pasos anteriores, pero en vez de apuntar a la URL de la instancia de URL, apunte a su servidor de Live Agent. Podrá encontrar su servidor de Live Agent dirigiéndose a Configuración y escribiendo "Configuración de Live Agent" en Configuración rápida. Verá una URL de extremo que tiene una apariencia parecida a "https://d.la1w1.salesforceliveagent.com/chat/rest/". Elimine "https://" y "/chat/rest/" y luego ejecute un comando traceroute sobre solo la parte "d.la1w1.salesforceliveagent.com" de la dirección.
Interpretación de los resultados de ping
El resultado de un ping tendrá un aspecto similar a este ejemplo al hacer ping a na17.salesforce.com a continuación:

Los resultados anteriores muestran una conexión rápida sin pérdida de paquetes. Las indicaciones de un problema incluirían:
- Pérdida de paquetes de un 10% o más. Hubo una pérdida del 0% en el ejemplo anterior.
- Una discrepancia entre los tiempos de ida y vuelta (RTT) mínimos, máximos y medios. Para el ejemplo anterior, los RTT mínimos fueron 104 ms, los máximos 107 ms los medios 104 ms. Estos resultados indican que hubo poca variación en la latencia durante un periodo de tiempo donde se capturaban los pings. No obstante, si los resultados fueran unos mínimos de 100 ms y unos máximos de 500 ms, esto indicaría que hay problemas con la latencia que provoca una conexión disminuida de forma intermitente.
Interpretación de los resultados de traceroute
Un comando traceroute mostrará datos estadísticos de rendimiento para cada salto en la ruta de red que realiza su equipo para llegar a Salesforce con el fin de ayudar a identificar dónde se están produciendo los problemas.
Terminología de traceroute
- Número de salto: El número de salto específico en la ruta desde el emisor en la ruta desde el emisor al destino.
- Tiempo de ida y vuelta (RTT): El tiempo que tarda un paquete en llegar a un salto y volver, mostrado en milisegundos (ms). De forma predeterminada, tracert envía tres paquetes a cada salto, de modo que el resultado enumera tres tiempos de ida y vuelta por salto. RTT también se conoce a veces como latencia. Un factor importante que puede afectar a RTT es la distancia física entre saltos. Para obtener una descripción más detallada y en profundidad de RTT y sus efectos, consulte el artículo Efectos del tiempo de ida y vuelta y el ancho de banda sobre el rendimiento.
- Nombre: El nombre de dominio completamente cualificado (FQDN) del sistema. Muchas veces el FQDN puede proporcionar una indicación de dónde está ubicado físicamente el salto. Si el Nombre no aparece en el resultado, no se encontró el FQDN. No es necesariamente indicativo de un problema, si no se encontró un FQDN.
- Dirección IP: La dirección del Protocolo de Internet (IP) de ese enrutador o host específico asociado con el nombre.
Los componentes de un traceroute
A continuación hay una ruta a la instancia nortemericana de Salesforce NA17 (tracert na17.salesforce.com):

La primera línea del resultado de tracert describe lo que está haciendo el comando. Enumera el sistema de destino (salesforce.com), la dirección IP de destino y el número máximo de saltos que se realizarán en el comando traceroute (30).
El primer salto es la parada inicial que realiza su tráfico cuando abandona su equipo. Probablemente será un número 10.X.X.X o un número 192.168.X.X. Estos están reservados para redes privadas y son también bastante habituales en un traceroute. Los primeros saltos de la ruta con estos prefijos de red están normalmente dentro de la red interna de su empresa. Más abajo en la ruta solo indican que el tráfico está pasando por la red interna del ISP antes de salir.
Identificación de problemas habituales
Los 3 números que ve son las veces individuales para llegar a ese salto específico. Es importante destacar que estos números no representan la diferencia de tiempo entre el salto actual y el anterior, sino que representan el tiempo acumulado empleado hasta ese salto. Cuando mire un traceroute busque el primer punto en el que haya un alto grado de variación entre los tiempos (por ejemplo: 50 ms 283 ms, 29 ms) o tiempos que sean constantemente mucho más altos que los del salto anterior. También podría ver “*” como una entrada. Estos indican que no se recibió respuesta desde el servidor. No representan necesariamente signos de un problema, especialmente una vez que llega a Salesforce. Ciertas redes no responden a los paquetes empleados en traceroute por motivos de seguridad o priorización. Una vez esté dentro del centro de datos, Salesforce hace lo mismo. Si ve un salto que agota el tiempo de espera, probablemente no es un problema siempre que la conexión se complete sistemáticamente. Es importante hacer notar que los resultados “normales” de su traceroute y ping variarán en base a la ubicación geográfica de tanto su sistema como del centro de datos. Por ejemplo, si se encuentra en Australia y está conectando con un centro de datos del este de EE.UU., un tiempo de ida y vuelta de 250-300 ms no es poco habitual debido a la distancia geográfica que debe recorrer físicamente la conexión a través de cables submarinos. No obstante, un tiempo de ida y vuelta de 300 ms desde Australia al centro de datos de Tokio sería poco habitual.
Los resultados de traceroute que muestran una latencia aumentada en un salto intermedio, que se mantiene similar todo el camino hasta el destino, no indican un problema de red. Un traceroute que muestra una latencia aumentada drásticamente en un salto intermedio, que luego aumenta sostenidamente hasta el destino, puede indicar un posible problema de red. Las pérdidas de paquetes o asteriscos (*) en muchos de los saltos intermedios pueden indicar un posible problema de red si el destino no está accesible o la latencia aumenta considerablemente en saltos posteriores. Una tendencia sostenida de latencia que en aumento es normalmente una indicación de congestión o un problema entre dos puntos de la red y requiere una o más partes para corregir el problema.
Para obtener más detalles sobre la interpretación de traceroute, consulte este PDF:
https://major.io/wp-content/uploads/2012/06/RAS_Traceroute_NANOG_slides.pdf
Asteriscos o mensajes "Se agotó el tiempo de espera de la solicitud"
Si un asterisco (*) aparece para RTT, entonces el paquete no se devolvió dentro del espacio de tiempo esperado. Uno o más asteriscos para un salto no indican necesariamente una pérdida de paquetes en el destino final.
Cuando aparecen tres asteriscos, verá un mensaje "Se agotó el tiempo de espera de la solicitud" en uno o más saltos de la ruta. Esto no indica necesariamente un problema de red o ISP, y la mayoría de las veces significa que esos saltos no están dando prioridad a paquetes ICMP (ping y traceroute). Podemos ver un ejemplo de ello a continuación:
Ya que se pudo llegar al destino, esto indica que no hubo pérdidas de reenvío en ninguno de los saltos intermedios y el nivel bajo de latencia sistemático al final de la conexión sustenta una conclusión de que no hay problemas de red.
Es posible que reciba tres asteriscos seguidos de “Se agotó el tiempo de espera de la solicitud” por los siguientes motivos:
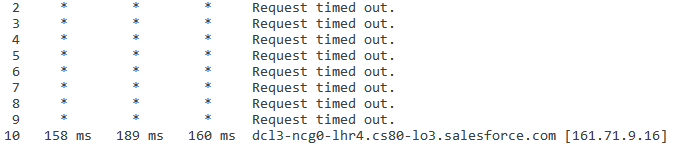
- Falta de prioridad de paquetes ICMP
- El cortafuegos del destino u otro dispositivo de seguridad está bloqueando la solicitud.
- Podría existir un problema en la ruta de retorno desde el sistema de destino. Recuerde que el tiempo de ida y vuelta mide el tiempo que tarda un paquete en viajar desde su sistema al sistema de destino y volver. La ruta de reenvío y la ruta de retorno a menudo siguen rutas diferentes. Si existe un problema en la ruta de retorno, podría no ser evidente en el resultado del comando.
- Podría existir un problema de conexión en ese sistema en particular o en el sistema siguiente.
Decisiones de enrutamiento insólitas
Los ISP están realizando constantemente mejoras en su redes alterando las decisiones de enrutamiento e incorporando nuevas líneas para mantener el buen estado de sus redes y optimizar ciertos patrones de tráfico. Ocasionalmente, estos cambios podrían enrutar sus solicitudes a Salesforce a través de una ruta que no sea la idónea. Por ejemplo, si está accediendo a una instancia de Salesforce en Norteamérica desde California pero se le está enrutando a través de Singapur y vuelta antes de alcanzar la aplicación, sufrirá ciertamente tiempos de carga aumentados. Puede identificar estos problemas de enrutamiento en traceroute examinando el nombre de los saltos, que los ISP tienden a etiquetar con información basada en la ubicación, y un pico en RTT de 100-200 durante 1 salto que es el comportamiento típico de un salto intercontinental.Si se encuentra en la misma región que su centro de datos (Norteamérica para instancias NAXX, Asia para APXX, Europa/África para EUXX) y observa un salto grande en su traceroute, puede dirigirse a [dirección IP].ipaddress.com para determinar la ubicación geográfica de la dirección IP específica donde se está produciendo el salto. Si detecta este tipo de problema, póngase en contacto con su ISP ya que pueden controlar la ruta que toma su solicitud a Salesforce.
Contacto con el Servicio de atención al cliente de Salesforce
Si no puede señalar ningún problema de red, envíe toda la información que haya recopilado realizando los pasos anteriores al Servicio de atención al cliente de Salesforce y analizaremos con detalle el problema. Además de los procesos de traceroute y ping descritos anteriormente, incluya también el acceso de inicio de sesión, los pasos para reproducir la lentitud que está sufriendo y el nombre de su Proveedor de servicios de Internet (ISP), así como si su ISP ha proporcionado cualquier perspectiva de la latencia.
Número del artículo de conocimiento
000385480
¿Resolvió este artículo su problema?
¡Háganos saber cómo podemos mejorar!