組織を選択
B2C Commerce 日本語カスタム辞書について
公開日: May 29, 2026
説明
概要
日本語での商品検索では、検索フレーズや商品名(厳密には検索可能属性)に対して、形態素解析(トークンの識別および分割)が行われます。このトークンの識別は、トークナイザーによってシステムに内蔵された形態素解析辞書に基づいて行われます。しかし、この辞書には標準的な日本語の形態素のみが登録されています。
また、日本語の処理においては、分割されたトークンに対して、動詞の活用形を基本形に変換したり、助詞(てにをは)を除去したりする処理も行われます。そのため、特に固有名詞が多く登場する EC サイトでは、検索フレーズが商品名に部分一致しているにもかかわらず、検索にヒットしないといった問題が発生する場合があります。この問題は、特にひらがなの処理において発生しやすい傾向があります。
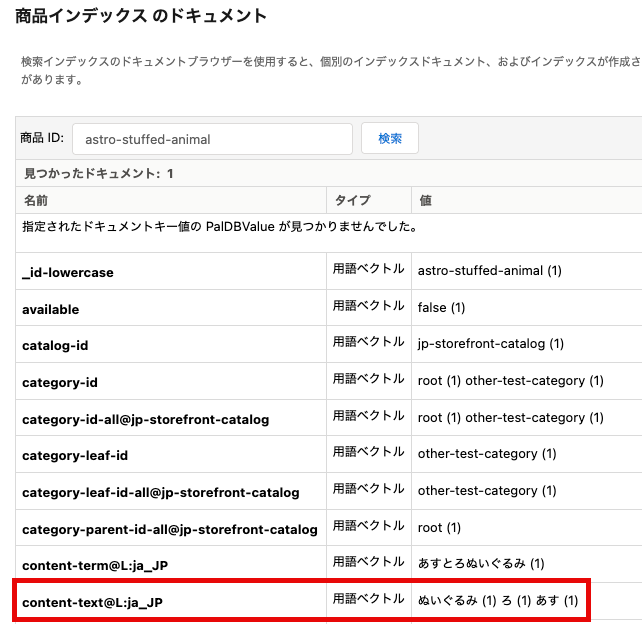
例えば、サイトのカタログに「あすとろぬいぐるみ」という商品があり、これを「あすとろ」というフレーズで検索するシナリオを想定してみましょう。
「あすとろ」は標準的な日本語ではないため、一つのトークンとして認識されません。その結果、「あすとろぬいぐるみ」は商品インデックス作成時のトークナイザーの内部アルゴリズムによって「あす」「と」「ろ」「ぬいぐるみ」に分割されます。その後、後続の処理によって助詞の「と」が除去され、最終的にこの商品は「あす」「ろ」「ぬいぐるみ」としてインデックス化されます。
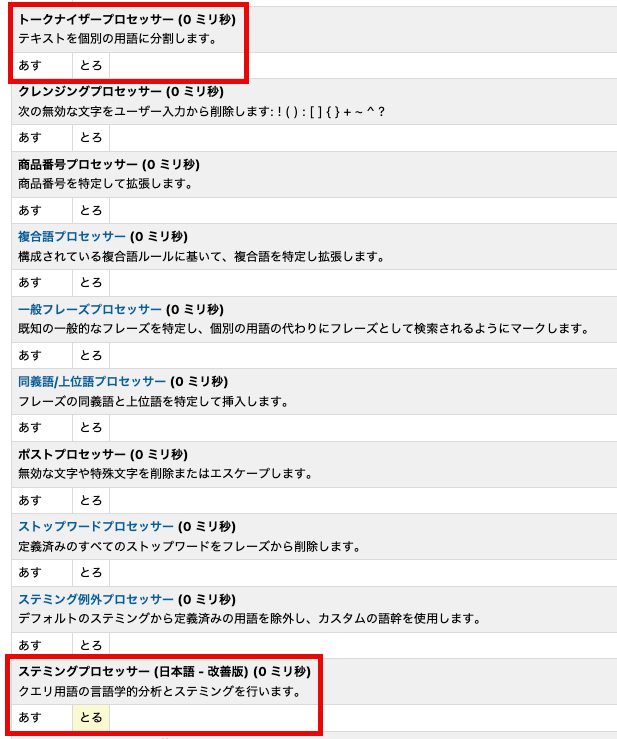
一方、検索フレーズの「あすとろ」についても一つのトークンとして認識されない点は同じですが、こちらの場合はフレーズが内部アルゴリズムによって「あす」「とろ」に分割されます。その後、後続の処理で「とろ」が動詞の活用形と判定されて基本形の「とる」に変換され、最終的な検索クエリは「あす」「とる」として生成されます。
このような理由から、「あすとろ」というフレーズで検索しても、「あすとろぬいぐるみ」が検索結果に表示されないという問題が発生します。
※なお、助詞の「と」が除去されたり、「とろ」(動詞)が基本形の「とる」に変換されたりする動作自体は、日本語処理として正しい振る舞いです。
| 「あすとろぬいぐるみ」の商品インデックス | 「あすとろ」の検索結果 |
 |  |
解決策
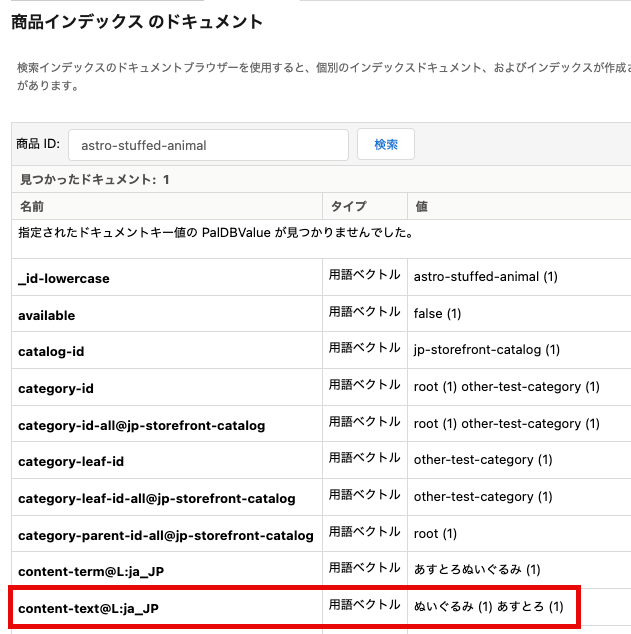
カスタム辞書は、「あすとろ」のようにトークンとして認識させたい単語を登録できる機能です。「あすとろ」をカスタム辞書に登録すると、「あすとろぬいぐるみ」は「あすとろ」「ぬいぐるみ」に正しく分割され、「あすとろ」が単一のトークンとして認識されます。これにより、「あすとろ」という検索フレーズで「あすとろぬいぐるみ」がヒットするようになります。
※カスタム辞書では「分割」項目にて単語がどのように分割されるかを指定することもできます。
| カスタム辞書への「あすとろ」登録後の「あすとろぬいぐるみ」の商品インデックス | カスタム辞書への「あすとろ」登録後の「あすとろ」の検索結果 |
 | 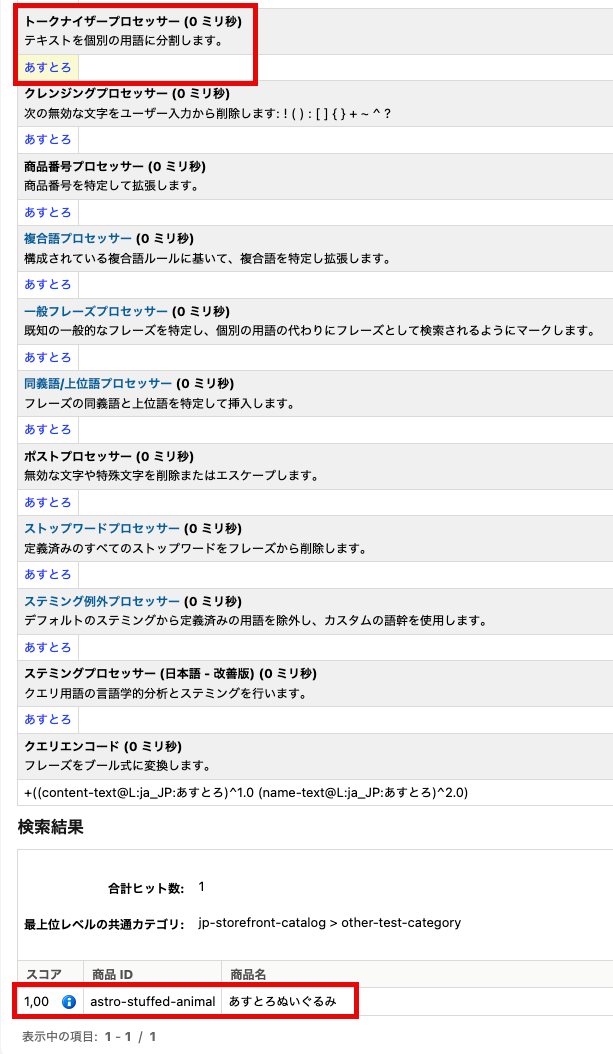 |
注意点
しかし、カスタム辞書を多用すると想定外の副作用が生じる可能性もあるため、不必要な単語の登録は避けるべきです。
例えば、「プリン」という単語をカスタム辞書に登録すると、「プリント」という単語が「プリン」と「ト」に分割されるようになってしまいます。その影響で、「プリン」と検索した際に、「プリント」を含む商品までヒットするようになります。
| カスタム辞書への「プリン」登録後の「プリント」の商品インデックス | カスタム辞書への「プリン」登録後の「プリン」の検索結果 |
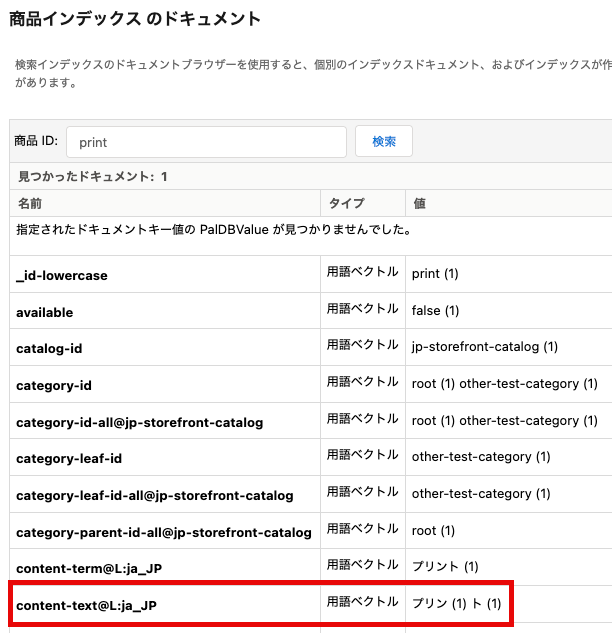 | 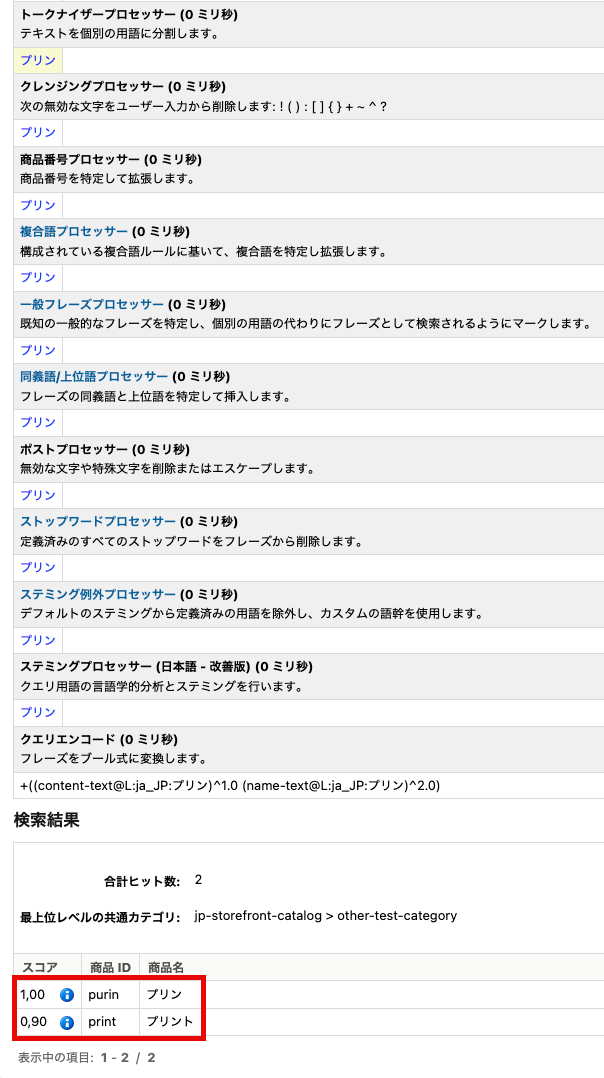 |
このように、カスタム辞書はトークナイザーの動作に直接的な影響を与える「諸刃の剣」です。したがって、カスタム辞書は、この機能を使わなければ解決できない問題が発生した場合にのみ、限定的に利用することが望ましいです。
カスタム辞書の設定箇所
カスタム辞書はサイト単位のデータであり、Business Manager の以下の二箇所で管理します。
- マーチャントツール > 検索 > 検索インデックス
- 画面右上の「言語オプション」をクリックし、遷移先の画面でカスタム辞書を管理します。
- ステミングが「日本語」または「日本語 - 改善版」の場合に設定できます(「日本語 - 改善版」を推奨)。
- クラシック UI では表示・設定できません。
- マーチャントツール > 検索 > インポート & エクスポート
- 「検索設定」にてカスタム辞書を XML 形式で一括インポート・エクスポートできます。
カスタム辞書エントリーの入力項目
単語(surface-form)
登録したい単語を入力します。
- 例
- あすとろ
- 東京スカイツリー
分割(segmentation)
スペース区切りでトークンの分割を指定します。
トークンを分割せず、一つのまとまりとして認識させたい場合は、「単語」項目と同じ文字列を入力します。
- 例
- あすとろ
- 東京 スカイツリー
フリガナ(furigana)
単語の読み方をカタカナで入力します。
「分割」項目でスペース区切りを指定した場合は、フリガナも同様にスペースで区切って入力します。
※補足:ふりがな自体は日本語検索の動作に直接影響しませんが、システムの仕様上、入力必須項目となっています。
- 例
- アストロ
- トウキョウ スカイツリー
品詞(part-of-speech)
単語に該当する品詞(例:名詞、副詞)を適宜選択、または入力します。
カスタム辞書 XML データの例
<?xml version="1.0" encoding="UTF-8"?>
<search xmlns="http://www.demandware.com/xml/impex/search2/2010-02-19">
<user-dictionaries>
<japanese-user-dictionary xml:lang="ja-JP">
<user-dictionary-entry>
<surface-form>あすとろ</surface-form>
<segmentation>あすとろ</segmentation>
<furigana>アストロ</furigana>
<part-of-speech>名詞</part-of-speech>
</user-dictionary-entry>
<user-dictionary-entry>
<surface-form>東京スカイツリー</surface-form>
<segmentation>東京 スカイツリー</segmentation>
<furigana>トウキョウ スカイツリー</furigana>
<part-of-speech>名詞</part-of-speech>
</user-dictionary-entry>
</japanese-user-dictionary>
</user-dictionaries>
</search>
本番環境への反映の流れ
カスタム辞書は、検索インデックスの作成とクエリ生成の両方の処理に影響を与えます。また、カスタム辞書はサイトの「検索インデックス」項目にてレプリケーションが可能です。
Staging 環境から本番環境への反映の流れは以下の通りです。
- Staging 環境でカスタム辞書のエントリーを適宜登録・編集する。
- Staging 環境の「マーチャントツール > 検索 > 検索インデックス」にてサイトの検索インデックスを再作成する。
- Staging 環境にて検索動作を確認する。
詳細な動作確認は「マーチャントツール > 検索 > 検索インデックスのクエリテスト」にて実施できます。 - サイト配下の「検索インデックス」項目のレプリケーションを実行することで、本番環境へ検索インデックスおよびカスタム辞書データを反映する。
補足:日本語検索の品質向上のための推奨設定
日本語検索の品質を向上させるための設定として、カスタム辞書のほかに、「日本語検索とインデックスの厳密な整合」機能と、言語オプションの「日本語 - 改善版」ステミングがあります。これらの機能については、以下のように設定することを強く推奨します。
- 日本語検索とインデックスの厳密な整合の有効化:チェックを入れる
- 設定箇所:管理 > グローバル環境設定 > 機能スイッチ
- ステミング:「日本語 - 改善版」
- 設定箇所:マーチャントツール > 検索 > 検索インデックス > 言語オプション
日本語検索に関する問題を確認した場合は、まず上記の設定の変更をお試しいただくことを推奨します。これらの設定にて問題が解消されない場合に、カスタム辞書の利用をご検討いただくことを推奨します。詳しくは以下のナレッジ記事をご参照ください。
ナレッジ記事番号
005318805
この記事で問題は解決されましたか?
ご意見をお待ちしております。