
Usted está aquí:
Crear un modelo desde cero
Cree un modelo que utilice datos históricos para predecir resultados futuros. Seleccione y estructure su origen de datos y defina el resultado que desee. A continuación entrene el modelo para revelar inferencias y perspectivas predictivas utilizando IA, aprendizaje automático y análisis estadístico.
Para entrenar un modelo, estos son algunos requisitos de datos a tener en cuenta.
| Requisito | Mínimo | Máximo |
|---|---|---|
| Número de filas | 400 | 20 millones 5 millones para el algoritmo XGBoost |
| Número de variables (campos o columnas) | 3 (1 variable de resultado más otros 2 campos) | 50 con selección manual 350 con selección automática. Desde estos campos, Piloto automático considera solo los 50 más relevantes. |
-
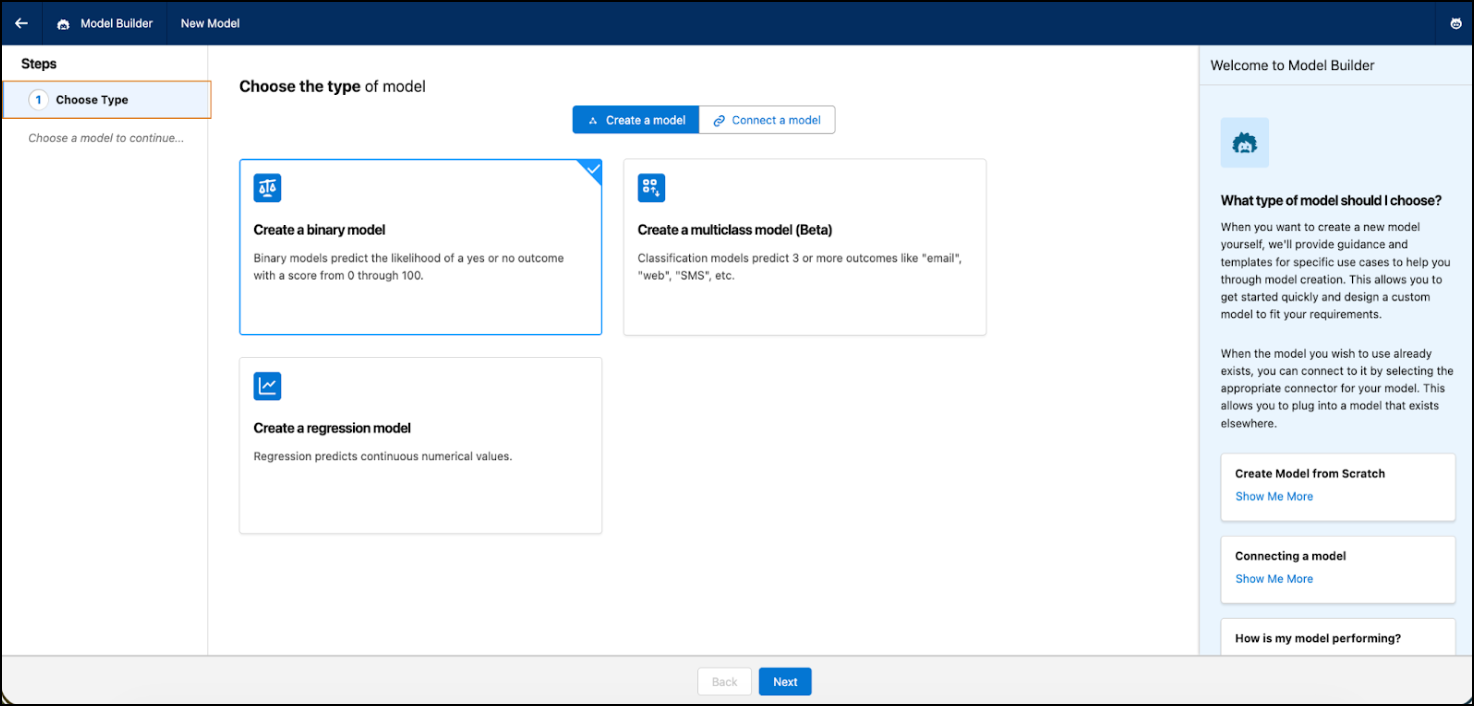
Seleccionar tipo
Dependiendo de su caso de uso, seleccione un modelo binario, de regresión o de clases múltiples (beta).
 Nota
NotaLos modelos de clasificación son un servicio piloto o beta que está sujeto a las Condiciones de servicios beta en Acuerdos - Salesforce.com o un Acuerdo piloto unificado escrito si lo ejecuta el Cliente, y las condiciones aplicables en el Directorio de condiciones de productos. El uso de este servicio piloto o beta es a la única discreción del Cliente.
-
Seleccionar datos
Seleccione el origen de datos con el que entrenar su modelo. Einstein utiliza los datos para entrenar y probar el modelo.Al seleccionar un origen de datos, considere aportar algunas preguntas de orientación.
Pregunta Orientación ¿Qué resultado (como un KPI) desea predecir? El modelado predictivo detecta patrones relacionados con tres tipos de casos de uso: regresión (números continuos), clasificación binaria (resultados de texto de dos valores) o clasificación múltiple (de 3 a 10 posibles resultados). Los candidatos de datos ideales para modelado predictivo suelen implicar KPI asociados con grandes volúmenes de datos y muchas decisiones comerciales. ¿Qué variables desea incluir? La decisión de qué variables incluir afecta a la calidad y la interpretabilidad de un modelo predictivo. Cuando las variables son significativas y relevantes, se simplifican para las partes interesadas y los usuarios comerciales para comprender las relaciones entre factores y confiar en los resultados predichos. ¿Dónde puede encontrar esta información? Comprender de dónde proceden los datos es valioso en la evaluación de la calidad, la identificación de sesgos y la adhesión a la normativa y cumplimiento de los datos. -
Seleccionar datos de entrenamiento
Utilice todos los registros en el origen de datos para entrenar el modelo. O bien, especifique condiciones para restringir los registros utilizados para entrenar el modelo.
- Para seleccionar un subconjunto específico de datos para entrenar el modelo, haga clic en Conjunto filtrado de registros.
-
Defina su condición de filtro.
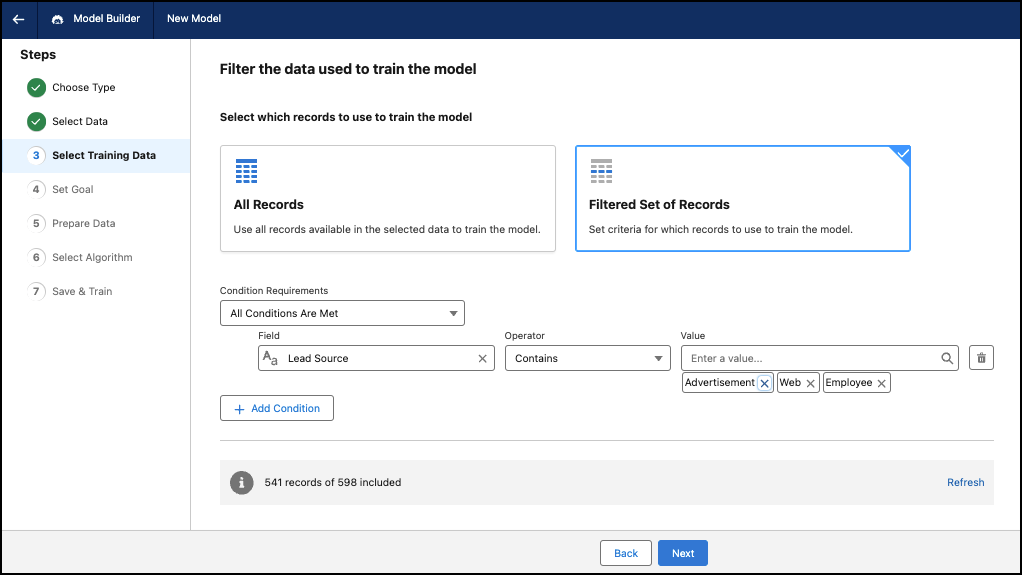
Lógica Descripción Requisitos de condición Se cumplen todas las condiciones: si todas las condiciones son verdaderas, se aplica el filtro. Si una de las condiciones es falsa, no se aplica el filtro.
Se cumple cualquier condición: si una condición es verdadera, se aplica el filtro.
Campo Basada en el origen de datos. El atributo o la variable de datos que se utilizará cuando se aplique el filtro. Operador Define la relación entre el campo y la condición. Los operadores disponibles dependen del tipo de campo. Valor Valor específico para evaluar el campo. Para los campos de texto, seleccione uno o varios valores. Para campos numéricos, introduzca un valor. Para los campos de fecha, utilice el calendario para seleccionar una fecha.
-
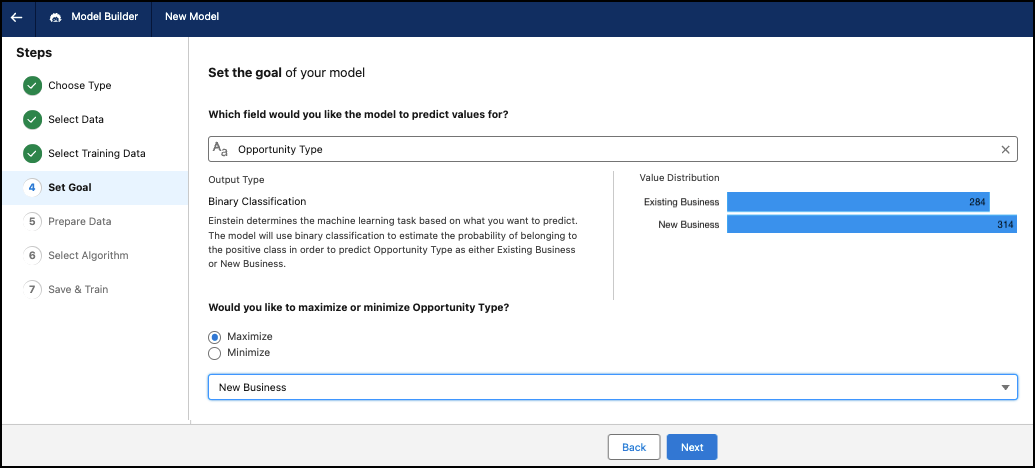
Establecer un objetivo
Seleccione un problema comercial que desee resolver. Examine los indicadores clave de rendimiento (KPI) que desea mejorar. Explore qué KPI candidatos pueden beneficiarse más de la implementación de una solución con tecnología de IA.
- Seleccione el campo para el que desea predecir valores. Decida qué variable de resultado desea explorar y en qué granularidad. La variable de resultado podría ser un valor de KPI (como ingresos, descuento, medición de coste o duración) u otro resultado cuantificable. También puede utilizar categorías (campos de texto) con dos valores (binarios) como una variable de resultado.
- Seleccione maximizar o minimizar su objetivo. Einstein construye y entrena un modelo centrado en maximizar o minimizar la variable de resultado. Por ejemplo, su objetivo puede ser maximizar el margen neto o minimizar el abandono de clientes. Einstein construye un modelo centrado en alcanzar un mayor margen neto o reducir el abandono de clientes.
-
Preparar datos
Seleccione qué campos incluir como variables en el modelo. Asegúrese de que las variables son relevantes para el resultado comercial que desea predecir. Restrinja los datos para proporcionar mejores resultados utilizando variables precisas, completas y representativas de operaciones comerciales reales en términos de cantidad (volumen) y variación (diversidad). No utilice campos que contengan datos confidenciales o información de identificación personal (PII).
-
Seleccionar algoritmo
El algoritmo es el enfoque o el procedimiento computacional que emplea el modelo para aprender de los datos y realizar predicciones. También puede activar Selección automática, de modo que Einstein puede seleccionar automáticamente un algoritmo con el mayor impacto en su predicción y caso de uso.
-
Seleccione el algoritmo para su modelo.
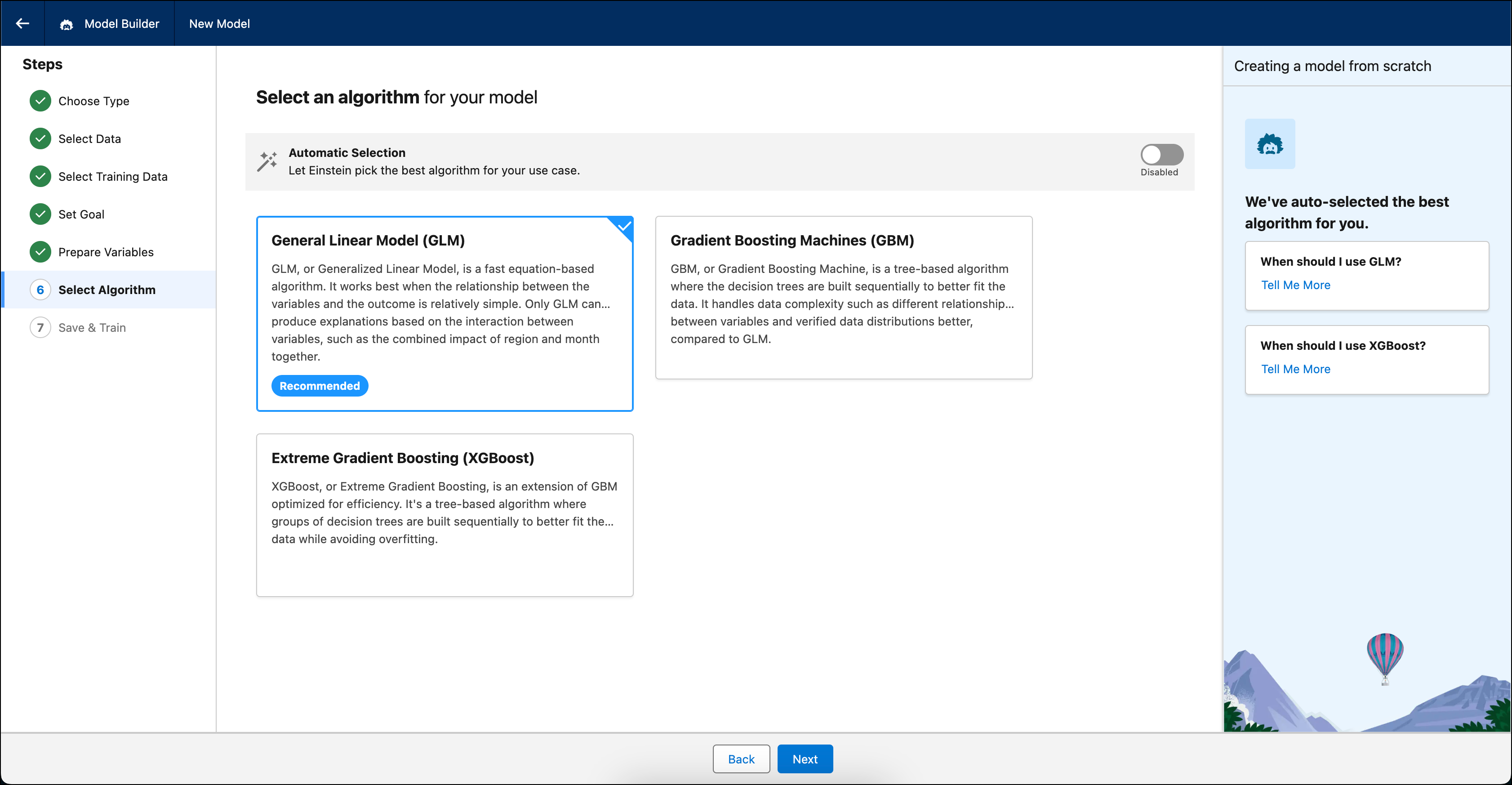
Algoritmo Descripción GLM predeterminado. Modelo lineal generalizado (GLM) es un algoritmo basado en ecuaciones que normalmente se completa rápidamente. Funciona mejor cuando la relación entre las variables y el resultado es relativamente sencilla. Solo GLM puede producir explicaciones basándose en la interacción entre variables, como el impacto combinado de región y mes juntos. GBM Máquina de potenciación del gradiente (GBM) es un algoritmo basado en árboles donde los árboles de decisiones están construidos secuencialmente para ajustarse mejor a los datos. Gestiona la complejidad de los datos, como, por ejemplo, las diferentes relaciones entre variables y distribuciones de datos variables mejor en comparación con GLM. XGBoost Potenciación del gradiente extremo (XGBoost) es una extensión de GBM optimizada para la eficiencia. Es un algoritmo basado en árboles donde los grupos de árboles de decisiones se crean de forma secuencial para ajustarse mejor a los datos, a la vez que evitan sobreajustes.
-
Seleccione el algoritmo para su modelo.
-
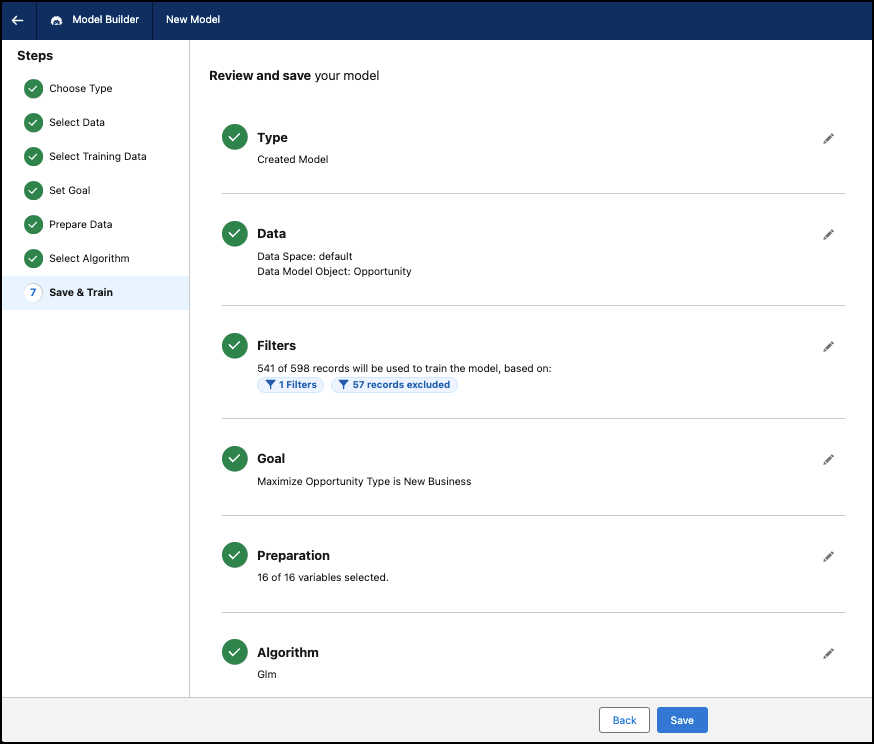
Revisar y entrenar
Entrene su modelo después de revisar los detalles.
-
Revise los detalles del modelo. Opcionalmente, haga clic en el icono de lápiz para modificar un paso.
Nota
Puede modificar todos los pasos al crear un modelo. Después de crear el modelo, no puede modificar pasos como: Seleccione Tipo, Seleccionar datos y Establecer objetivo.
-
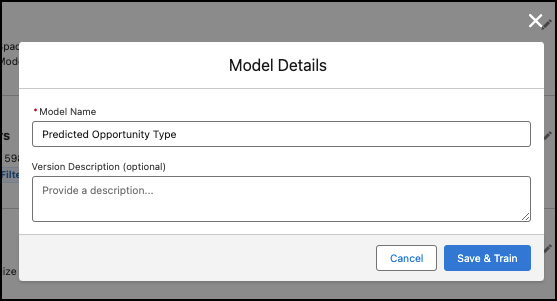
Haga clic en Guardar para introducir un nombre y una descripción opcional para su modelo, y haga clic en Guardar y entrenar para crear el modelo.
-
Revise los detalles del modelo. Opcionalmente, haga clic en el icono de lápiz para modificar un paso.
Einstein analiza los datos y entrena el modelo basándose en su configuración. La creación de modelos tarda tiempo y Einstein muestra su progreso en el camino de modo que sabe cuántos minutos quedan.
Tras crear el modelo, podrá encontrarlo en la ficha Modelos predictivos en Einstein Studio. Consulte Inicio Einstein Studio.
- Solucionar problemas en los datos
Gestione problemas comunes que puede encontrar cuando prepare datos para la creación de modelos y después de entrenar un modelo. - Aplicar transformaciones a sus datos
Transforme datos de modelado para mejorar la fiabilidad, precisión y explicabilidad de predicciones. Para modelos creados desde cero (creados por Einstein), Model Builder transforma automáticamente texto no estructurado y sustituye datos que faltan. También puede transformar manualmente variables en modelos binarios o de regresión.