
Vous êtes ici :
Création d'un modèle de toutes pièces
Créez un modèle qui utilise des données historiques pour prédire les résultats futurs. Sélectionnez et structurez votre source de données et définissez le résultat souhaité. Entraînez ensuite le modèle à révéler des inférences et des connaissances prédictives en utilisant l'IA, l'apprentissage machine et l'analyse statistique.
Pour entraîner un modèle, voici quelques exigences en données à prendre en compte.
| Exigence | Minimum | Maximum |
|---|---|---|
| Nombre de lignes | 400 | 20 millions 5 millions pour l'algorithme XGBoost |
| Nombre de variables (champs ou colonnes) | 3 (1 variable de résultat plus 2 autres champs) | 50 avec sélection manuelle 350 avec sélection automatique. À partir de ces champs, Autopilot prend en compte uniquement les 50 champs les plus pertinents. |
-
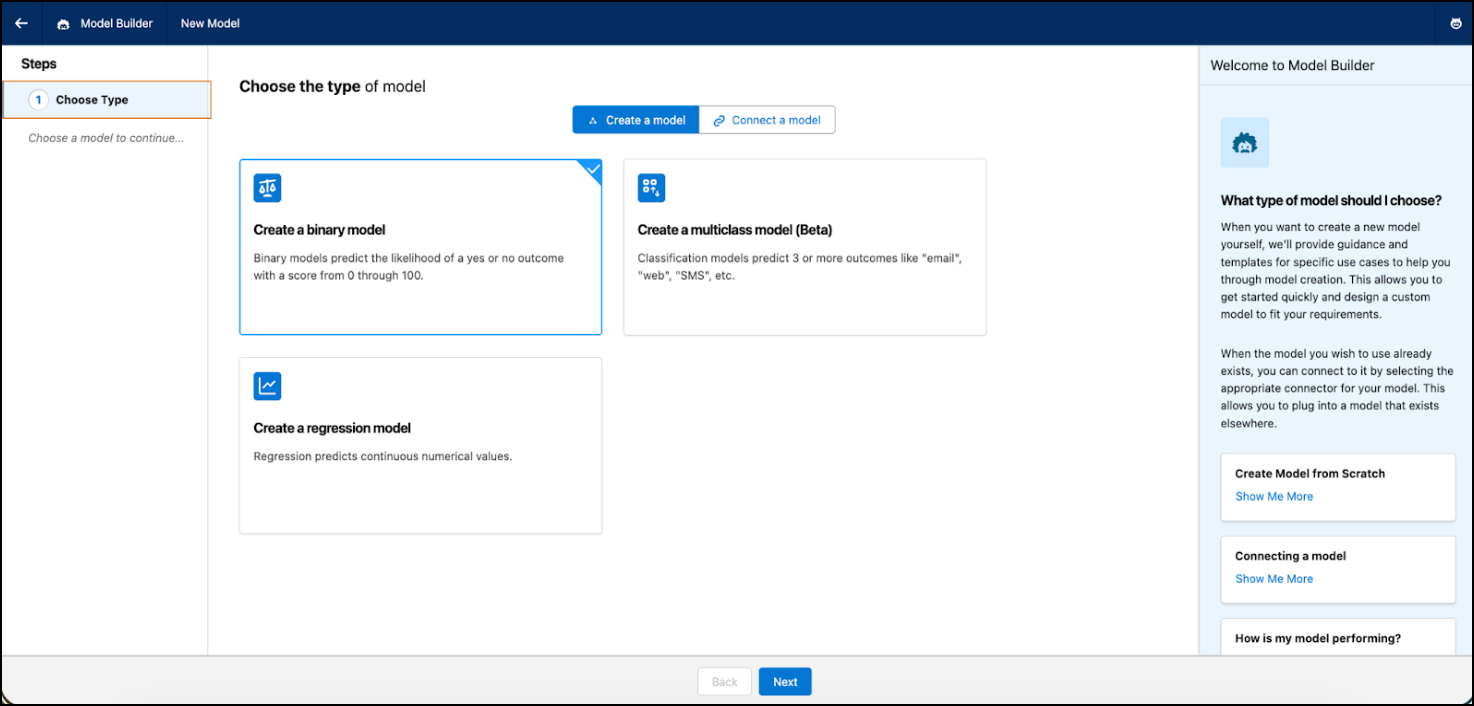
Choisir le type
Selon votre cas d'utilisation, sélectionnez un modèle binaire, de régression ou multiclasses (bêta).
 Remarque
RemarqueLes modèles de classification sont un service pilote ou bêta soumis aux Conditions des services bêta dans Accords - Salesforce.com ou un document écrit Unified Pilot Agreement si exécuté par le Client, et aux conditions applicables énoncées dans le Répertoire des conditions du produit. L'utilisation de ce service pilote ou bêta est à la seule discrétion du Client.
-
Sélectionner des données
Sélectionnez la source de données avec laquelle entraîner votre modèle. Einstein utilise les données pour entraîner et tester le modèle.Lors de la sélection d'une source de données, répondez à quelques questions d’ordre général.
Question Guide Quel résultat (par exemple un indicateur de performance clé) voulez-vous prédire ? La modélisation prédictive détecte les modèles associés à trois types de cas d'utilisation : régression (nombres continus), classification binaire (résultats de texte à deux valeurs) ou classification multiple (de 3 à 10 résultats possibles). Les candidats aux données idéales pour la modélisation prédictive impliquent souvent des indicateurs de performance clés associés à des volumes de données importants et à de nombreuses décisions métiers. Quelles variables souhaitez-vous inclure ? Le choix des variables à inclure impacte la qualité et l'interprétabilité d'un modèle prédictif. Lorsque les variables sont pertinentes, elles aident les parties prenantes et les commerciaux à comprendre les relations entre les facteurs et à faire confiance aux résultats prédits. Où trouver ces informations ? Comprendre la source des données est important pour évaluer la qualité, identifier les biais, et adhérer à la gouvernance et la conformité des données. -
Sélectionner des données d'entraînement
Utilisez tous les enregistrements de la source de données pour entraîner le modèle. Vous pouvez également spécifier des conditions pour restreindre les enregistrements utilisés pour entraîner le modèle.
- Pour sélectionner un sous-ensemble de données spécifique pour entraîner le modèle, cliquez sur Ensemble d'enregistrements filtrés.
-
Définissez votre condition de filtrage.
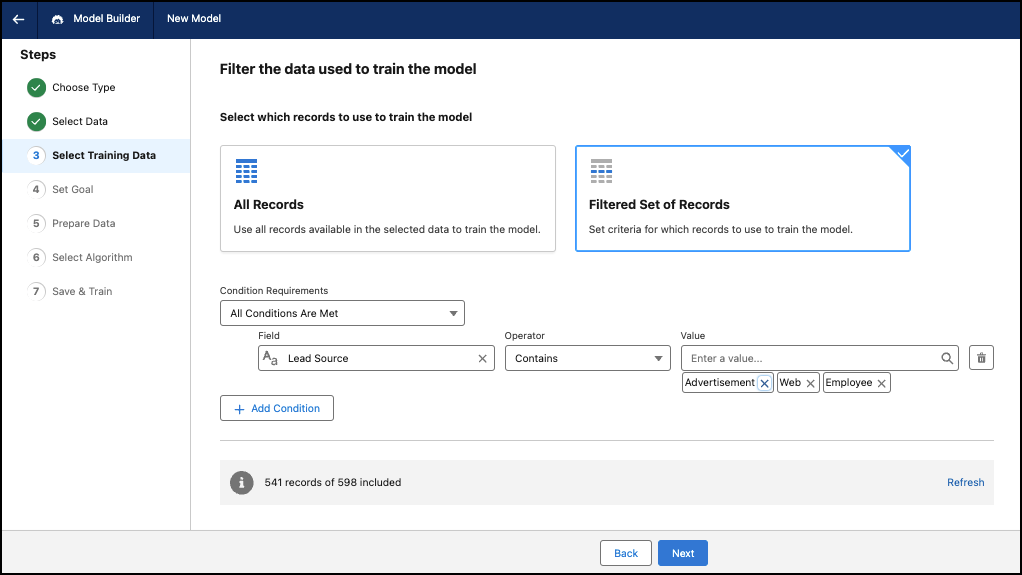
Logique Description Exigences de condition Toutes les conditions sont remplies : si toutes les conditions sont remplies, le filtre est appliqué. Si l'une des conditions est false, le filtre n'est pas appliqué.
N'importe quelle condition est remplie : si une condition est vraie, le filtre est appliqué.
Champ Basée sur la source de données. L'attribut ou la variable de données à utiliser lors de l'application du filtre. Opérateur Définit la relation entre le champ et la condition. Les opérateurs disponibles dépendent du type de champ. Valeur La valeur spécifique à évaluer dans le champ. Pour des champs de texte, sélectionnez une ou plusieurs valeurs. Pour des champs numériques, saisissez une valeur. Pour des champs de date, sélectionnez la date dans le calendrier.
-
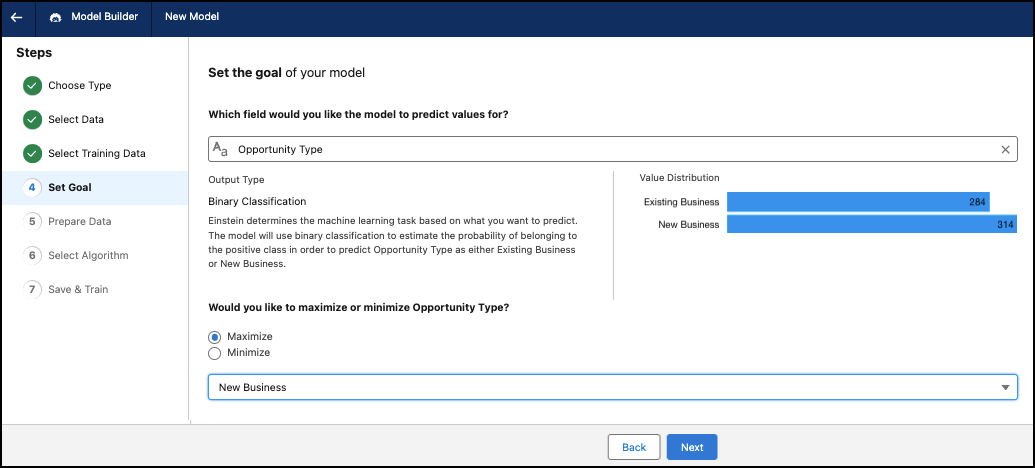
Définir un objectif
Sélectionnez un problème métier que vous souhaitez résoudre. Examinez les indicateurs de performance clés (KPI) que vous souhaitez améliorer. Explorez les indicateurs de performance clés candidats qui peuvent bénéficier le plus du déploiement d'une solution pilotée par l'IA.
- Sélectionnez le champ dont vous souhaitez prédire les valeurs. Déterminez quelle variable de résultat vous souhaitez explorer, et à quel niveau de granularité. La variable de résultat peut être la valeur d'un indicateur de performance clé (par exemple une mesure de chiffre d'affaires, de remise, de coût ou une durée) ou un autre résultat quantifiable. Vous pouvez également utiliser des catégories (champs de texte) avec deux valeurs (binaire) en tant que variable de résultat.
- Choisissez de maximiser ou de minimiser votre objectif. Einstein élabore et entraîne un modèle qui s'appuie sur l'augmentation ou la réduction de la variable de résultat. Par exemple, votre objectif peut consister à maximiser la marge nette ou à minimiser la perte de clientèle. Einstein élabore un modèle qui vise à atteindre un taux de marge net supérieur ou à réduire l'attrition des clients.
-
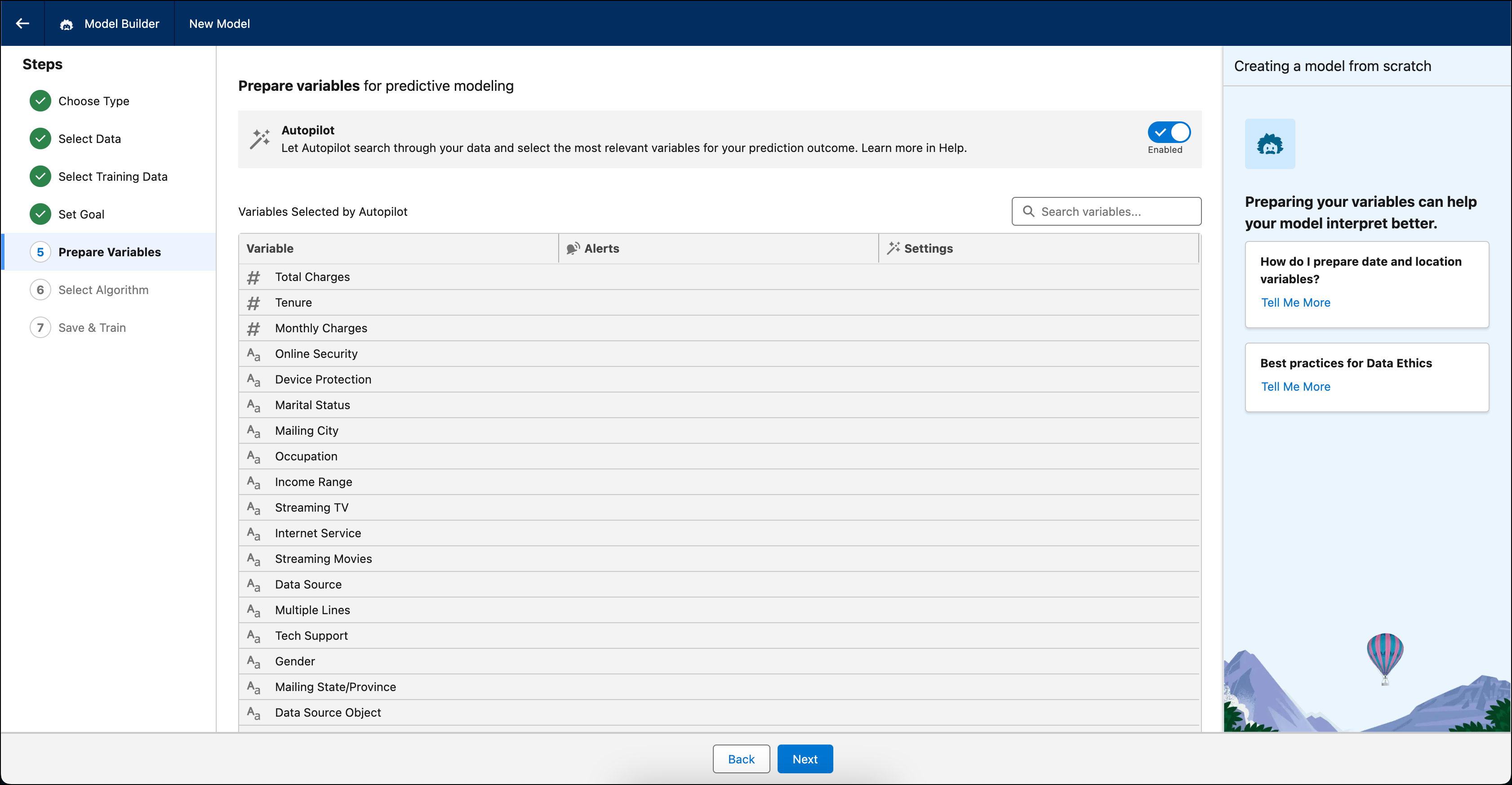
Préparer les données
Sélectionnez les champs à inclure en tant que variables dans le modèle. Assurez-vous que les variables sont pertinentes pour le résultat métier que vous souhaitez prédire. Affinez les données pour obtenir de meilleurs résultats en utilisant des variables précises, complètes et représentatives des opérations commerciales réelles en termes de quantité (volume) et de variation (diversité). N'utilisez pas de champs contenant des données confidentielles ou des informations d'identification personnelle (PII).
-
Sélectionner un algorithme
L'algorithme est l'approche, ou la procédure calculée, que le modèle suit pour apprendre à partir des données et établir des prédictions. Vous pouvez également activer la Sélection automatique, Einstein peut ainsi sélectionner automatiquement un algorithme ayant l'impact le plus élevé sur votre prédiction et votre cas d'utilisation.
-
Choisissez l'algorithme de votre modèle.
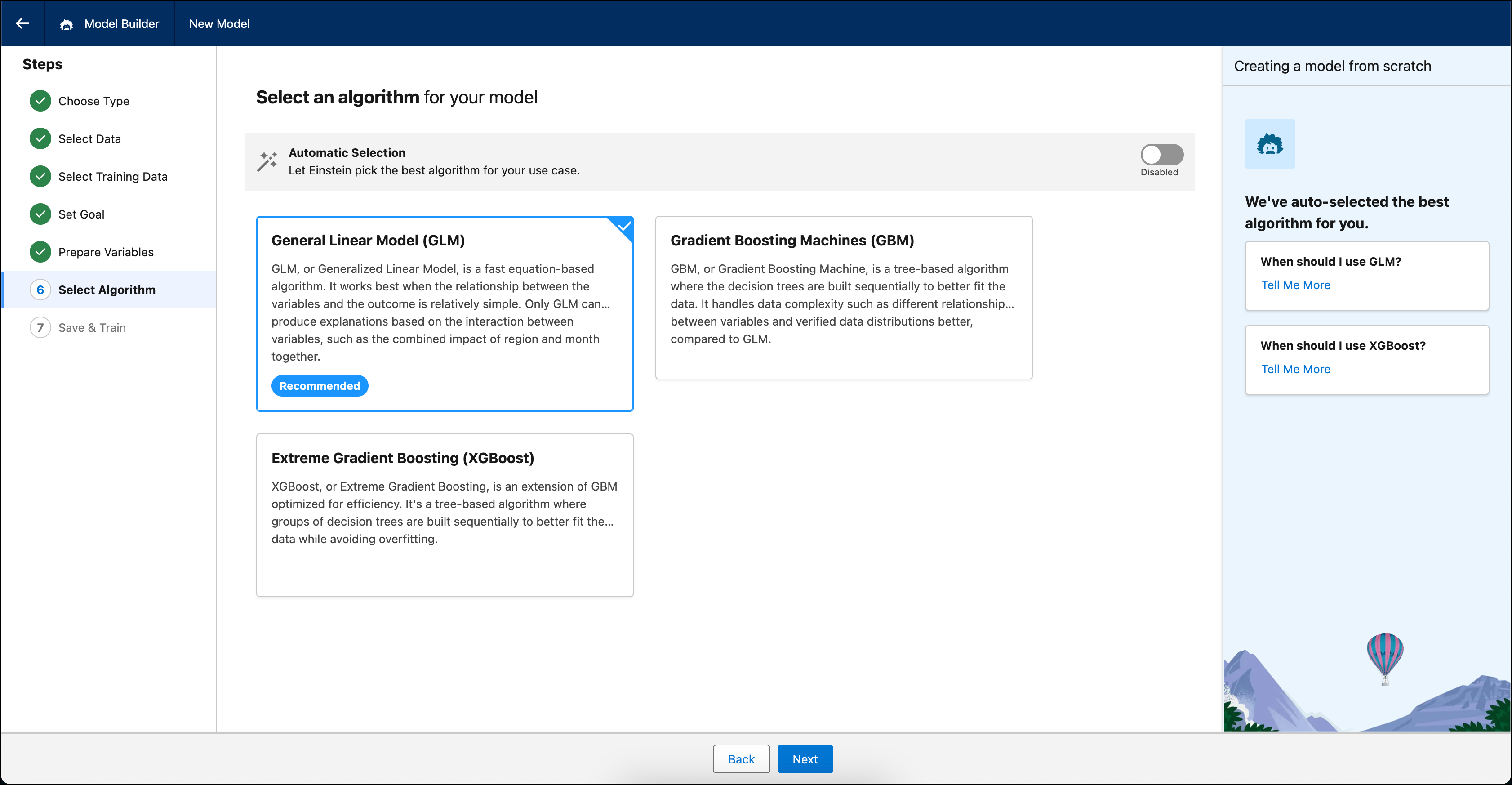
Algorithme Description MLG Par défaut. Le modèle linéaire généralisé (MLG) est un algorithme basé sur une équation qui se termine généralement rapidement. Il fonctionne mieux lorsque la relation entre les variables et le résultat est relativement simple. Seul le MLG peut générer des explications basées sur l'interaction entre des variables, par exemple l'impact combiné de la région et du mois. GBM Le Gradient Boosting Machine (GBM) est un algorithme basé sur un arbre, dans lequel les arbres de décision sont construits de façon séquentielle pour mieux s’adapter aux données. Par rapport au GLM, il gère mieux la complexité des données, par exemple les différentes relations entre les variables et les distributions de données variées. XGBoost Le XGBoost est une extension du GBM optimisée pour plus d’efficacité. Il correspond à un algorithme basé sur un arbre dans lequel des groupes d'arbres de décision sont construits de façon séquentielle pour mieux s’adapter aux données, tout en évitant un sur-apprentissage.
-
Choisissez l'algorithme de votre modèle.
-
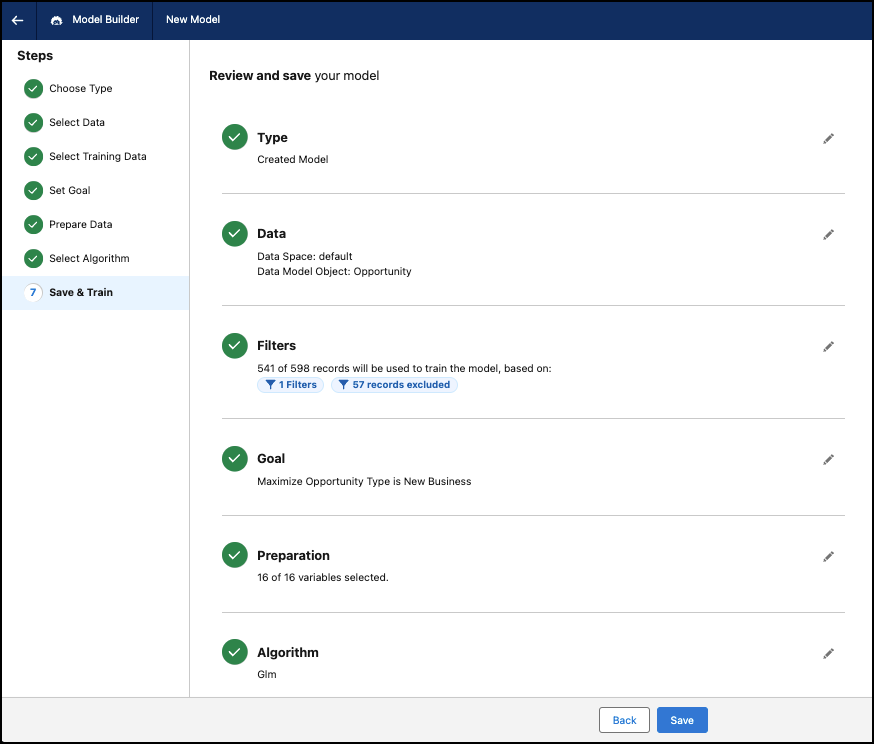
Vérification et entraînement
Entraînez votre modèle après avoir examiné les détails.
-
Vérifiez les détails du modèle. Vous pouvez également cliquer sur l'icône de crayon pour modifier une étape.
Remarque
Vous pouvez modifier toutes les étapes lors de la création d'un modèle. Une fois le modèle créé, vous ne pouvez pas modifier des étapes telles que : Choisissez Type, Sélectionner des données et Définir un objectif.
-
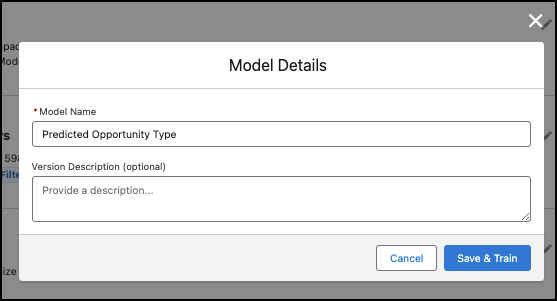
Cliquez sur Enregistrer pour saisir un nom et une description (facultative) de votre modèle, puis sur Enregistrer et entraîner pour créer le modèle.
-
Vérifiez les détails du modèle. Vous pouvez également cliquer sur l'icône de crayon pour modifier une étape.
Einstein analyse les données et entraîne le modèle en fonction de vos paramètres. La création d'un modèle prend du temps, et Einstein montre sa progression en cours de route pour que vous sachiez le nombre de minutes restantes.
Une fois le modèle créé, il se situe sous l'onglet Modèles prédictifs dans Einstein Studio. Consultez Accueil Einstein Studio.
- Résolution des problèmes de données
Gérez les problèmes courants que vous pouvez rencontrer en préparant des données pour l'élaboration d'un modèle et après avoir entraîné un modèle. - Application de transformations à vos données
Transformez les données de modélisation pour améliorer la fiabilité, la précision et l'explicabilité des prédictions. Pour les modèles créés de toutes pièces (créés par Einstein), le Générateur de modèle transforme automatiquement le texte non structuré et remplace les données manquantes. Vous pouvez également transformer manuellement des variables dans des modèles binaires ou de régression.