您位於此處:
混合式搜尋合併排名
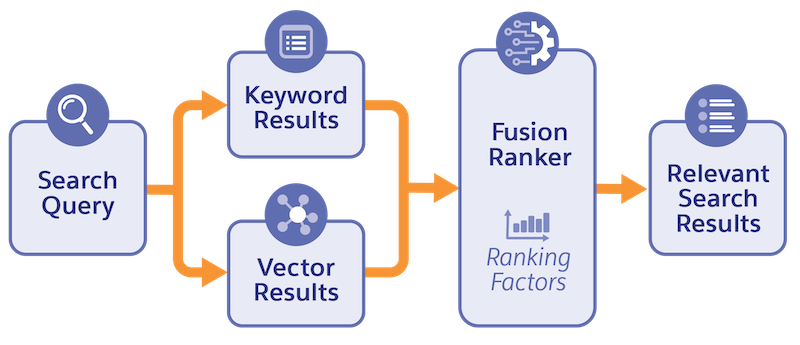
排名會將搜尋結果重新排序,讓與使用者查詢最相關的結果位於頂端。Data 360 混合式搜尋會根據與查詢的相似度,從兩個索引 (關鍵字和向量) 提取結果,然後合併 (合併) 結果。排名模型接著會將合併結果重新排名。
在設定期間,您可以設定其他排名因素 (例如記錄的最近程度和受歡迎程度) 來影響排名。排名係數以搜尋索引物件欄位或相關物件欄位為基礎。例如,您可以使用索引的 DMO 的 LastModifiedDate 欄位來定義記錄的最近時間。
Salesforce 合併排名模型已針對各種以搜尋為基礎的工作最佳化內部基準。基準會測量效能的精確度、穩定性和敏感性,以產生高品質的模型。評估的條件是透過搜尋回應和註解的使用者互動組合來進行精密設計。訓練和評估資料是以從 Salesforce Einstein 搜尋和 RAG 應用程式 (例如 Einstein 搜尋答案 ⁇ 取的查詢為基礎。
有許多因素會影響向量與關鍵字搜尋的相似度分數。例如,關鍵字相似度分數取決於查詢文字和搜尋索引 DMO 的內容。向量相似度分數取決於查詢文字和搜尋索引的特定內嵌模型。合併排名模型會傳回一個混合搜尋分數,其為關鍵字和向量相似度分數與排名因素的線性組合。
為了提供一般混合式搜尋使用個案的最佳結果,系統會針對最佳組合微調模型,其中包含每個評分的正規化策略以及每個評分的加權。合併排名模型會根據衍生的混合搜尋分數決定結果的最終排名。即使其中一個搜尋相似度分數為零,模型仍可將具有高混合式搜尋分數的結果排名。例如,若相對於相同搜尋查詢的替代結果其向量分數,其向量分數足夠高,則具有零關鍵字分數的結果可能會得到高混合式搜尋分數。
| 搜尋類型 | 分數參數 | 描述 |
|---|---|---|
| 向量搜尋 | vector_score__c | 由指定查詢的基礎向量搜尋索引傳回的相似度分數。 |
| 關鍵字搜尋 | keyword_score__c | 由指定查詢的基礎關鍵字搜尋索引傳回的相似度分數。 |
| 混合搜尋 | hybrid_score__c | 從合併關鍵字和向量分數衍生的分數。此分數會取得排名因素。例如文件受歡迎程度與最近程度,請考量。此分數決定結果的排名。 |
範例 請考慮使用具有特定網域字詞 (例如「V2MOM」) 的搜尋字串進行混合式搜尋查詢。排名模型會傳回向量分數、關鍵字分數和混合式搜尋分數,然後將結果集排名。
select * from hybrid_search(
table(<Search_Index_DMO>),
"When is the V2MOM due?",
<Pre-Filter Fields>, <Limit Results>);
| 區塊識別碼 | 向量分數 | 關鍵字分數 | 混合式分數 | 最終排名 |
|---|---|---|---|---|
| A | 0.85 | 10.0 | 0.9 | 1 |
| B | 0.90 | 1.0 | 0.8 | 2 個 |
| C | 0.80 | 0.5 | 0.6 | 3 |
| D | 0.75 | 0.01 | 0.5 | 4 |
範例 在此範例中,混合式搜尋查詢包含受歡迎程度和最近排名因素,這會影響最終排名。

select * from hybrid_search(
table(<Search_Index_DMO>),
"How do I reset the password for my Acme account?",
<Pre-Filter Fields>, <Limit Results>);
| 區塊識別碼 | 向量分數 | 關鍵字分數 | 受歡迎 | 最近 (天) | 混合式分數 | 最終排名 |
|---|---|---|---|---|---|---|
| A | 0.91 | 10.0 | 1000 個 (高受歡迎程度) | 10 (最近) | 0.9 | 1 |
| B | 0.90 | 10.5 | 1 | 15 | 0.875 | 2 個 |
| C | 0.80 | 2 個 | 5 | 25 | 0.8 | 3 |
| D | 0.80 | 1 | 10 通 | 100 | 0.75 | 4 |
備註 這些範例顯示如何從關鍵字和向量相似度分數以及排名因素衍生混合式搜尋分數。分數值並非絕對值,且實際上只能用來比較相同查詢的排名結果。
此文章是否解決您的問題?
請讓我們知道,以便我們改進!