
Vous êtes ici :
Utilisation de la génération augmentée de récupération
Retrieval Augmented Generation (RAG) dans Data 360 est une infrastructure d'ancrage des invites de grand modèle de langage (LLM). En augmentant l'invite avec des informations précises, à jour et pertinentes, RAG améliore la pertinence et la valeur des réponses LLM pour les utilisateurs.
Lorsque vous soumettez une invite LLM, RAG dans Data 360 :
- Récupère des informations pertinentes à partir de données structurées et non structurées indexées dans la base de données vectorielle de Data Cloud
- Augmente l'invite en combinant ces informations avec l'invite d'origine
- Génère une réponse rapide
Il est utile de penser à RAG en deux parties principales : préparation hors ligne et utilisation en ligne.
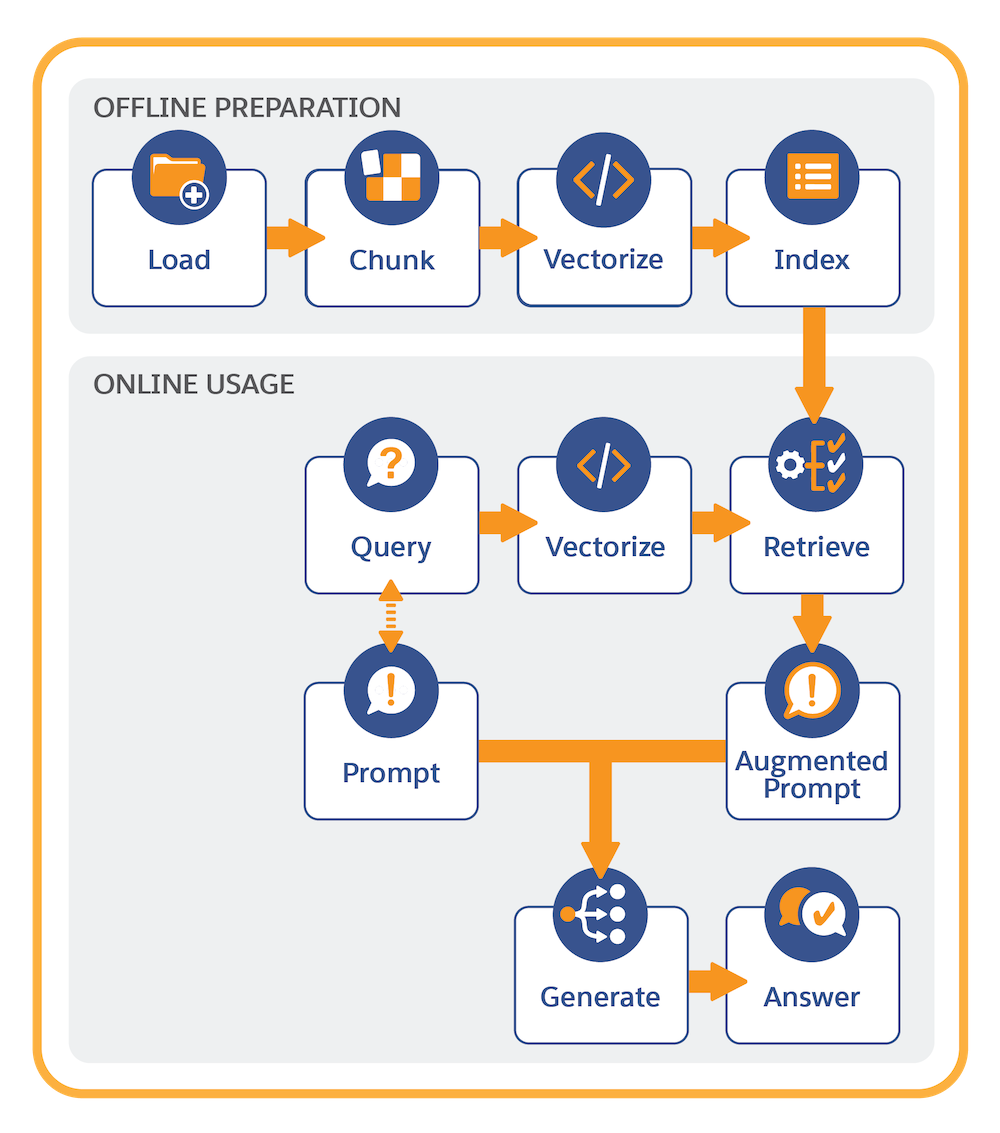
Préparation hors ligne
Pour implémenter RAG, commencez par connecter des données structurées et non structurées que RAG utilise pour ancrer les invites LLM.
Data 360 utilise une base de données vectorielle pour gérer les données non structurées. La base de données vectorielle contient une collection de contenus structurés et non structurés (un index de recherche) qui sont indexés de manière optimisée pour la recherche. Le contenu peut être ingéré à partir de diverses sources et types de fichier. Parmi les exemples de contenus non structurés utilisés avec RAG, mentionnons les réponses de service, les requêtes, les réponses de DP, les articles Knowledge, les courriels et les notes de réunion.
La préparation hors ligne comprend les étapes suivantes :
- Connectez vos données non structurées.
- Créez une configuration index de recherche pour segmenter et vectoriser le contenu.
La segmentation divise le texte en unités plus petites et sémantiquement significatives, et la vectorisation convertit les segments en représentations numériques du texte qui capturent les similitudes sémantiques.
- Stocker et gérer l'index de recherche dans Data 360.
Les récupérateurs servent de pont entre les index de recherche et les modèles d'invite. Les récupérateurs affinent les critères de recherche et récupèrent les informations les plus pertinentes utilisées pour augmenter les invites. Pour prendre en charge divers cas d'utilisation, vous créez des récupérateurs personnalisés dans Einstein Studio. Pour plus d'informations, consultez Récupération de données.
Utilisation en ligne
La dernière partie de l'implémentation RAG consiste à appeler un retriever dans un modèle d'invite. Pour un modèle d'invite donné, le concepteur d'invite peut personnaliser les paramètres de requête et de résultat du récupérateur afin de remplir une invite avec les informations les plus pertinentes.
L'utilisation en ligne implique les étapes suivantes :
- Le retriever est invoqué avec une requête dynamique initiée à partir du modèle d'invite.
- La requête est vectorisée (convertie en représentations numériques). La vectorisation active la recherche pour retrouver les correspondances sémantiques dans l'index de recherche.
- La requête récupère le contexte correspondant dans la base de données vectorielle de Data 360.
- L'invite d'origine est remplie avec les informations récupérées dans l'index de recherche.
- L'invite est soumise au grand livre, qui génère et renvoie la réponse de l'invite.
De nombreux LLM ont été formés généralement sur Internet à des contenus plus anciens. Avec RAG, les utilisateurs de modèles d'invite peuvent fournir au grand livre les informations les plus précises et les plus récentes, et apporter des données propriétaires au grand livre sans entraîner ni ajuster le modèle, créant ainsi des réponses générées plus pertinentes pour leur contexte et leur cas d'utilisation.