
Vous êtes ici :
Couche de Trust Einstein : Conçu pour Trust
Einstein Trust Layer est un ensemble de fonctionnalités, de processus et de politiques conçus pour protéger la confidentialité des données, améliorer la précision de l'IA et promouvoir une utilisation responsable de l'IA dans l'écosystème Salesforce.
Éditions requises
| Disponible avec : les éditions Enterprise, Performance et Unlimited avec un complément Einstein pour Sales, Einstein pour Platform, Einstein pour Service, Einstein 1 Service ou Einstein GPT Service. Pour acheter des compléments, contactez votre chargé de compte Salesforce. |
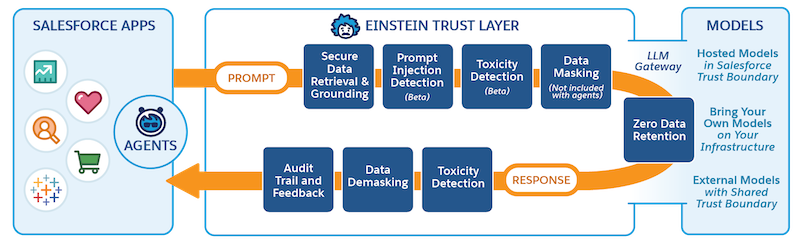
Pour comprendre le fonctionnement de la couche Trust Einstein, examinons comment les données transitent à travers la couche Trust puis parcourons en détail chaque partie du parcours.
- Les données, sous forme d'invite, transitent depuis les applications CRM, via la couche de Trust Einstein, vers le grand modèle de langage (LLM), que nous appellerons parcours d'invite.
- Le LLM génère une réponse en utilisant l'invite, que nous appellerons génération de réponse.
- La réponse générée reflue ensuite à travers la Couche de Trust Einstein et vers les applications CRM, que nous appellerons parcours de réponse.
Fonctionnement
Parcours d'invite
Pour générer une réponse à partir du grand livre, vous devez lui fournir une invite. L'invite peut provenir de n'importe quelle application CRM. Vous pouvez créer une invite dans le Générateur de répliques et l'invoquer depuis Apex ou un flux.
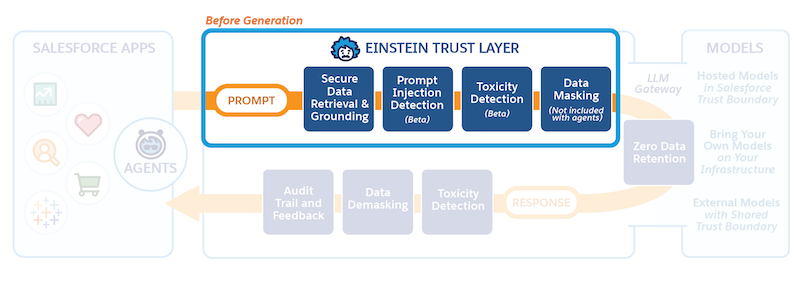
Sécurisation de la récupération et de l'ancrage des données
La première étape de la Trust Layer est la récupération sécurisée des données. Pour générer une réponse plus pertinente et personnalisée, le LLM nécessite un contexte supplémentaire à partir de vos données CRM. Ce processus d'ajout d'un contexte supplémentaire à l'invite est ce que nous appelons l'ancrage. Vous pouvez ancrer vos invites en utilisant des champs de fusion avec des données CRM, qui peuvent être des champs d'enregistrement, des flux, Apex, des objets modèle de données Data 360 et des listes associées.
La récupération de données sécurisée signifie que l'invite est basée uniquement sur des données auxquelles l'utilisateur exécutant a accès.
Le processus de récupération de données respecte les contrôles d'accès et les autorisations existants dans Salesforce :
- La récupération des données pour ancrer l'invite est basée sur les autorisations de l'utilisateur qui exécute l'invite.
- La récupération des données pour l'ancrage de l'invite préserve tous les contrôles Salesforce standard basés sur le rôle pour les autorisations utilisateur et la sécurité au niveau du champ lors de l'ancrage des données de votre instance CRM.
L'ancrage est dynamique, car il se produit à l'exécution et dépend de l'accès de l'utilisateur.
Masquage des données pour le LLM
Les stratégies Einstein Trust Layer incluent le masquage des données, où les données confidentielles sont détectées puis masquées. Nous identifions les données confidentielles en utilisant deux méthodes :
- Basé sur un modèle : Nous utilisons des modèles et un contexte pour identifier les données confidentielles dans le texte de l'invite. Plus précisément, nous utilisons des modèles d'expression régulière (regex) et des mots de contexte. Nous utilisons également des modèles d'apprentissage machine entraînés pour identifier les données qui n'ont pas de schéma défini, par exemple les noms de personnes ou d'entreprises.
- Basé sur le champ : Nous utilisons les métadonnées des champs classés en utilisant Shield Platform Encryption ou la classification des données pour identifier les champs confidentiels. Cela étend la classification que vous avez déjà appliquée à vos données dans votre organisation au masquage des données LLM.
Une fois identifiées, les données sont ensuite masquées avec un texte d'espace réservé afin d'empêcher leur exposition à des modèles externes. Einstein Trust Layer stocke temporairement les relations entre les entités d'origine et leurs espaces réservés respectifs. La relation est utilisée ultérieurement pour démasquer les données dans la réponse générée.
Défense des invites
Pour aider à réduire la probabilité que le LLM génère quelque chose d'involontaire ou de nuisible, Générateur de répliques et API Connect Modèle d'invite utilisent des stratégies système. Les stratégies système sont une série d'instructions à l'intention du LLM pour savoir comment se comporter d'une certaine façon pour établir Trust avec les utilisateurs. Par exemple, nous pouvons demander au LLM de ne pas traiter le contenu ou de générer des réponses dont il n'a pas d'informations. Les stratégies système sont un moyen de se défendre contre les attaques par jailbreaking et injection rapide.
Génération de réponses
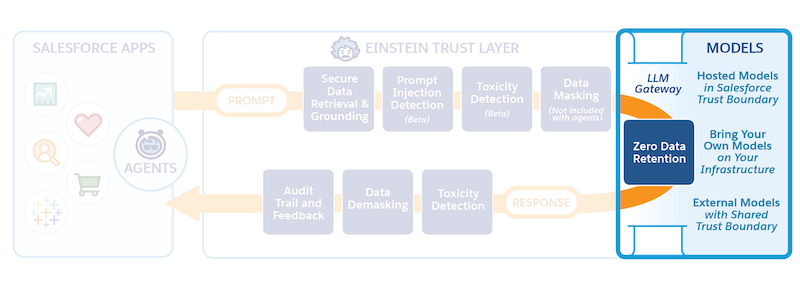
Lorsqu'une invite est entièrement hydratée et sécurisée, elle peut être envoyée via la passerelle LLM. La passerelle régit les interactions avec différents fournisseurs de modèle et représente une méthode unifiée et sécurisée pour communiquer avec plusieurs grands modèles de langage. Les fournisseurs de passerelle et de modèle utilisent le cryptage TLS pour s'assurer que les données sont sécurisées pendant le transit.
Les modèles élaborés ou ajustés par Salesforce sont hébergés dans la limite Salesforce Trust. Les modèles externes élaborés et gérés par des fournisseurs tiers, tels que OpenAI, se situent dans une frontière Trust partagée. Les modèles que vous élaborez et gérez sont hébergés dans votre infrastructure.
Nous avons mis en place une politique de rétention des données zéro avec des fournisseurs de modèles partenaires externes, tels que OpenAI ou Azure OpenAI. La stratégie stipule que les données envoyées au grand livre depuis Salesforce ne sont pas conservées et sont supprimées lorsqu'une réponse est renvoyée à Salesforce.
Couche de Trust Einstein : Le parcours de réponse
Lorsque la réponse générée est renvoyée à partir du grand modèle de langage, la Einstein Trust Layer applique certaines stratégies et processus pour s'assurer que la réponse est sûre et utile. Voir Einstein Trust Layer: Journey Response.