毒性检测
Einstein Trust 层使用机器学习 (ML) 模型来识别和标记提示和响应中的有毒内容。
所需的 Edition
| 适用于:Enterprise、Performance 和 Unlimited Edition,带有 Einstein for Sales、Einstein for Platform、Einstein for Service、Einstein 1 Service 或 Einstein GPT Service 加载项。要购买加载项,请联系您的 Salesforce 客户主管。 |
AI 应用程序中面向客户的输出代表贵公司的品牌和声音。AI 有时会生成有毒或有害内容,导致贵公司声誉受损。反应中的毒性也会受提示的影响,因此检测提示和反应中的毒性也很重要。提示中的毒性可能来自不可信的来源,例如公共聊天交互和第三方 Web 内容。
备注 响应中的毒性检测默认启用,并且无法更改。默认情况下,关闭提示中的毒性检测 (Beta),但您可以为您的 Salesforce 组织启用它。
当在提示或响应中检测到毒性时,您会在运行时在 Salesforce AI 功能中看到通知或警告。例如,如果在 LLM 生成的响应中检测到有毒内容,您会在副驾驶或提示生成器中看到有毒警告。
备注 免责声明:毒性警告并非在所有 AI 功能中可用。
提示生成器中的毒性警告
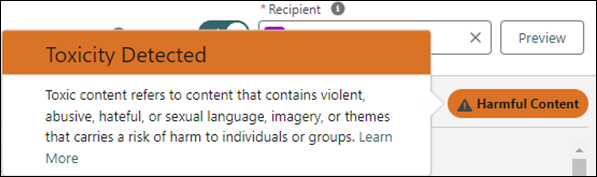
重要 虽然我们的毒性检测模型在内部测试期间被证明是有效的,但重要的是要注意,没有一个模型能够保证 100% 的准确性。此外,跨区域和跨国用例会影响检测特定数据模式的能力。以 Trust 为重,我们致力于对模型进行持续评估和完善。
毒性类别
Einstein 毒性检测模型识别这些类别:
| 类别 | 内容类型 |
|---|---|
| 暴力 | 描述、引用或煽动旨在对人、动物或财产造成身体伤害的行为的内容 |
| 性 | 描述、引用或引诱包含性语言、图像或主题的材料、行为或语言的内容,包括自愿和非自愿的性内容、非法和合法的性行为和行为,以及性暗示和调情内容 |
| 亵渎 | 包含煽动性、冒犯性、淫秽、粗俗或不敬的语言、手势和傲慢的内容 |
| 仇恨 | 描述、引用或煽动旨在基于身份或其他显著个人特征对个人或群体造成心理伤害的行为或语言的内容 |
| 物理 | 描述、引用、鼓励或允许使用、获取或分销非法物质、非处方药和其他在消费时具有生理或心理影响的物质的内容,或旨在造成身体伤害、自我伤害或死亡的行为 |
毒性得分
对每种有毒内容进行评级,以表明文本中该类型有毒语言的可能性。此外,Einstein Trust 层会提供总体毒性分数,反映所有检测到类别的组合。
得分范围从 0 到 1,其中 1 毒性最强。得分记录在审计跟踪中,并存储在 Data 360 中。 Trust 层预构建报表和仪表板在功能和时间上可视化毒性趋势。您也可以在 Data 360 中创建自定义报表。
另请参阅:
本文章是否解决您的问题?
请与我们共享您的想法,以便我们进行改进!