配置文本变量
为模型中的单个文本变量配置设置。
所需的 Edition
备注 Einstein Discovery 数据趋势图现在是模型。我们希望可以随时随地更新名称,但是在我们替换之前,您可能会在一些地方看到以前的名称。
| 适用于 Salesforce Classic 和 Lightning Experience。 |
| 适用于 CRM Analytics,另行付费后适用于 Enterprise、Performance 和 Unlimited Edition。此外,也适用于 Developer Edition。 |
| 所需用户权限 | |
|---|---|
| 要在模型中配置文本字段: | 创建和更新 Einstein Discovery 模型 |
-
在模型设置页面中,单击文本变量。会出现变量面板。
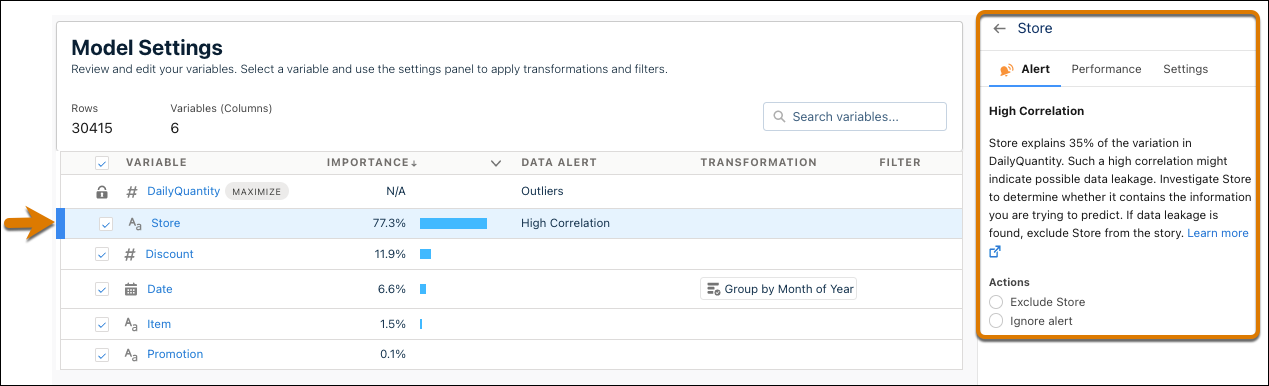
-
在警报选项卡中,回复与此字段的数据问题相关的任何建议,例如高相关性、最强预测值或缺失值。有关详细信息,请参阅处理质量警报。
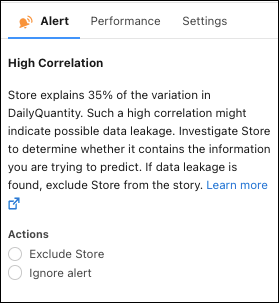
-
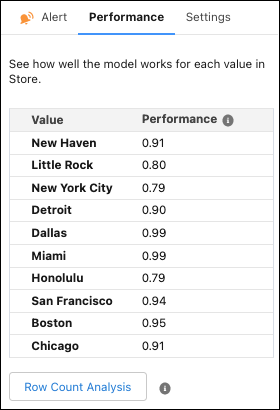
在性能选项卡中,查看您的模型对所选变量中的每个值的工作效果。
性能以十进制分数表示,其中 1 表示完全准确。例如,在变量商店中,迈阿密的绩效得分为 0.99,檀香山的绩效得分为 0.79。然后,您可以得出结论,该模型在迈阿密商店的表现优于檀香山商店。
-
或者,如果使用二元分类或回归模型,单击行数分析,以查看按性能和行数划分的值的详细比较。
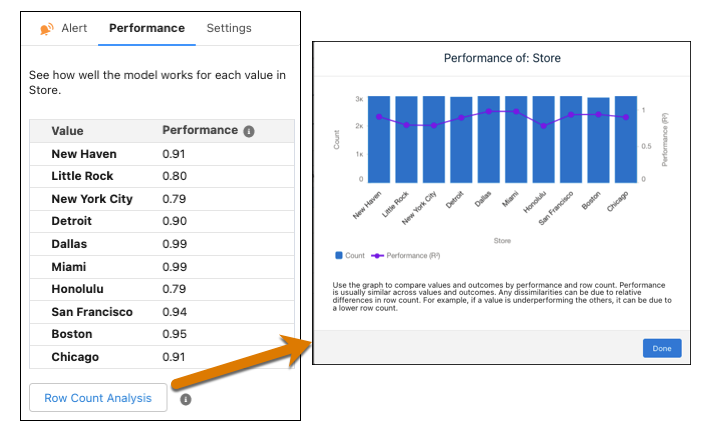
-
或者,如果使用多类分类模型,按结果查看每个值的性能。
- 要展开值以查看按结果划分的性能,请单击
 。
。- 要按性能和行数查看数值和结果的图形比较,请单击行数分析。
- 使用下拉列表选择不同的结果 (1)。图表根据选定结果更新。
- 在实际类和预测类之间切换 (2)。实际类根据观察值对数据进行分组。预测类根据预测值对数据进行分组。
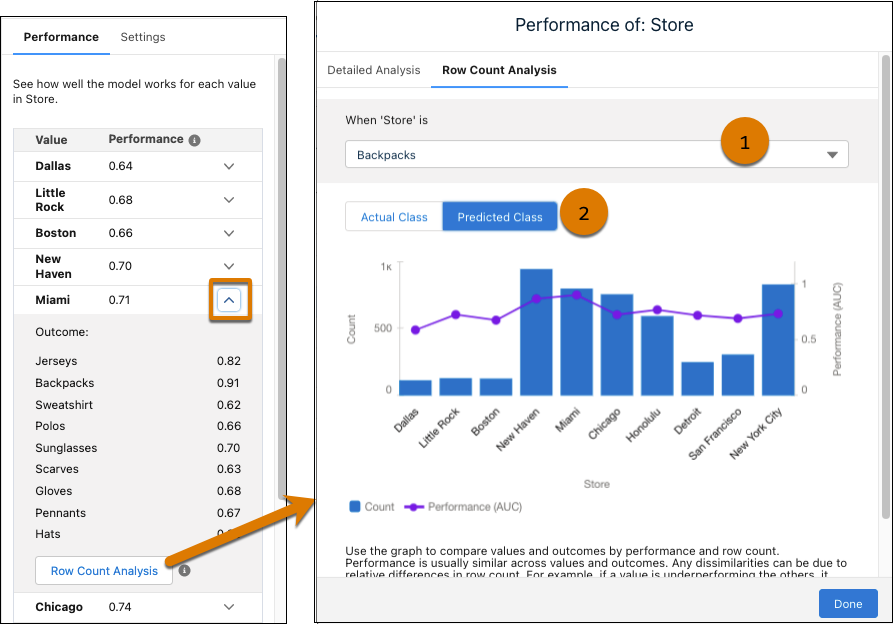
- 要按性能和行数查看数值和结果的图形比较,请单击行数分析。
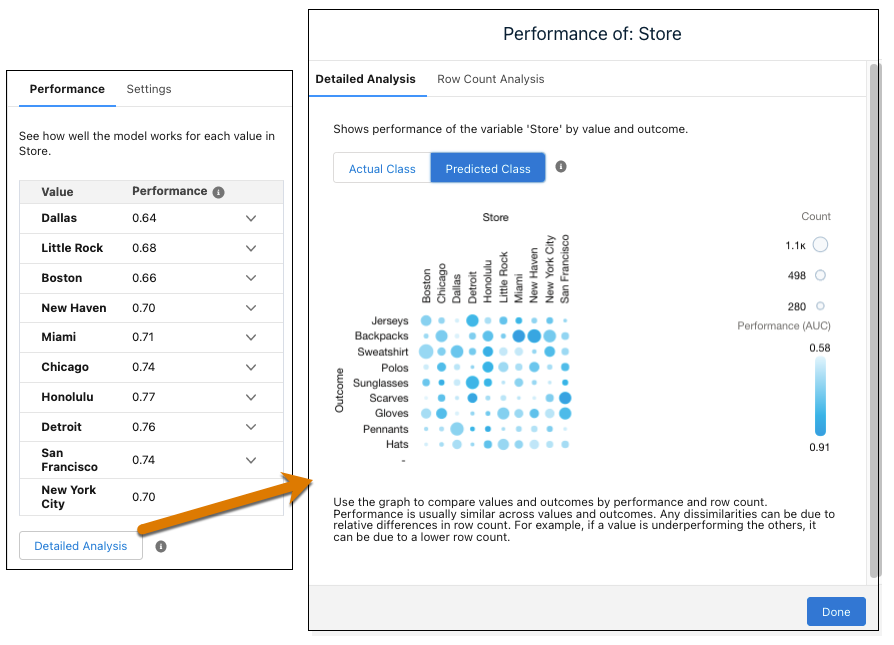
- 要按值和结果查看性能图表,请单击详细分析。圆圈越暗,性能越好。圆圈越大,行计数越高。
- 要展开值以查看按结果划分的性能,请单击
-
或者,如果使用二元分类或回归模型,单击行数分析,以查看按性能和行数划分的值的详细比较。
-
在设置选项卡中,配置以下设置。
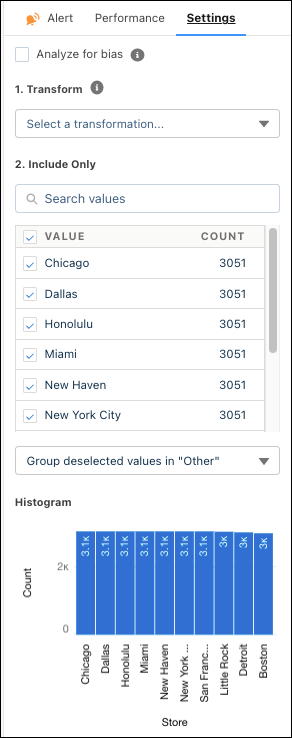
设置 说明 分析偏见 选择此选项可从模型中排除某个变量,以便它不会影响预测和建议。如果选中,Einstein Discovery 将在洞察标题旁边显示一个屏蔽图标,提醒您这是一个敏感变量。

此选项允许您评估变量在模型中的影响。如果 Einstein Discovery 显示与模型的结果变量有 50% 或更高的相关性,它仍然会通知您。
转换 选择转换文本的方法:
- 模糊匹配,解决拼写变化。请参阅应用模糊匹配实现更智能的分类。
- 检测情绪,对非结构化数据进行分类。请参阅检测非结构化文本中的情绪。
- 文本集群,按关键字存储未分类的数据。请参阅使用文本集群分析非结构化数据。
- 替换缺失的值,填写缺失的值。请参阅插补缺失文本值。
仅包括 选择要包含在模型中的值。根据以下选项,已排除值从分析中忽略,或合并到“其他”类别。 直方图 条形图显示值之间出现的值的数量。 创建模型后,更改将生效。
- 应用模糊匹配实现更智能的分类
模糊匹配增加了变量拼写变化的一致性,从而产生更智能的分类和更精准的预测。Einstein Discovery 在预测时转换数据,使您能够在数据准备期间跳过清理。 - 检测非结构化文本中的情绪
在模型创建过程中处理非结构化数据,并将情绪分类为积极、消极或中立。 - 使用文本集群分析非结构化数据
文本集群将非结构化数据减少到最重要的关键词,使您能够快速揭示隐藏的见解并改进决策。 - 插补缺失文本值
Einstein Discovery 允许您插补数据集中缺失的文本值。对文本变量启用插补,Einstein Discovery 会自动使用从数据的另一个子集导出的数据替换缺失的值。
本文章是否解决您的问题?
请与我们共享您的想法,以便我们进行改进!