您在此处:
Amazon S3 连接
使用 Amazon S3 连接器,创建远程连接,以将来自 S3 存储桶的 CSV 数据同步到 CRM Analytics。
连接详细信息
对于配置此连接器,了解 S3 存储桶文件夹层次结构至关重要。在创建连接时,设置 S3 存储桶设置和父文件夹路径。然后,选择一个或多个对象;这些对象是父文件夹路径中的子文件夹,并包含要同步到 CRM Analytics 的 CSV 文件。在同步连接的对象时,CRM Analytics 将查找名为 schema_sample.csv 的 CSV 文件,以检测文件夹内部 CSV 数据的架构并显示数据预览。但请注意,不会从 schema_sample.csv 文件导入数据。在此预览中,您可以查看和更改从文件夹加载的所有文件的字段属性。
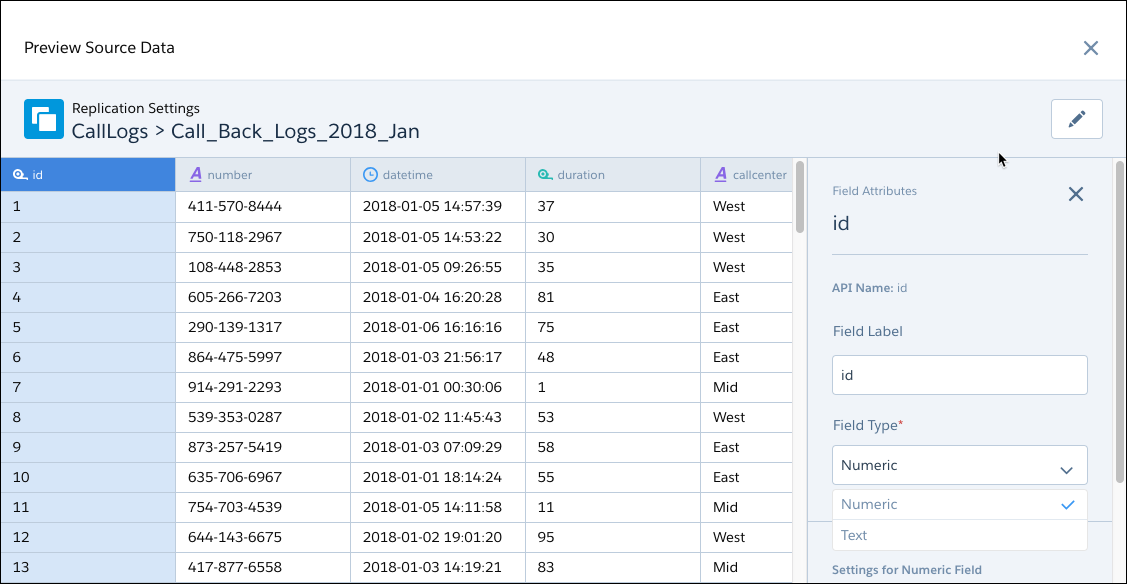
CRM Analytics 使用 schema_sample.csv 派生可用字段,因此您可以选择所需的字段。然后,连接器加载与子文件夹中选定字段集匹配的 CSV 文件,并在单个对象中附加行。
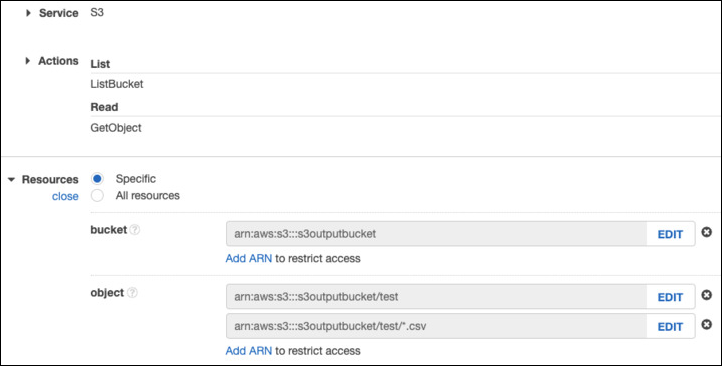
用于创建此连接的 Amazon S3 帐户的权限必须包括 ListBucket 和 GetObject。权限必须包括对存储桶和“任何对象”的资源授权,或者,如果您选择了特定的权限,还必须包括代表被引用的路径和对象的适当的 ARN。例如:
创建连接
- 在“数据管理器连接”选项卡中单击新建连接。
- 单击连接器的名称,然后单击下一步。
- 输入连接器设置。
- 要验证您的设置并尝试连接到源,请单击保存并测试。如果连接失败,CRM Analytics 会显示可能原因。
除非另行说明,否则所有设置需要值。
| 设置 | 描述 |
|---|---|
| 连接名称 | 识别连接。使用约定,可让您在区分不同连接。 |
| 开发人员名称 | 连接的 API 名称。此名称不能包含空格。API 名称会在模式中使用,以引用通过此连接提取的数据。您无法在创建连接后更改开发人员名称。 |
| 描述 | 连接的描述。 |
| 验证类型 | 对于标准身份验证,输入根。对于 AWS 身份访问管理 (IAM) 身份验证,输入 IAM。对于 AWS 数据的精细访问,请使用 IAM 身份验证,在 AWS 中设置 IAM 用户和角色。有关 AWS IAM 的更多信息,请查看 AWS 上 IAM 入门 |
| 访问密钥 | 您的 Amazon S3 存储器访问密钥 ID。 |
| 密钥 | 您的 Amazon 密码访问密钥。 |
| AWS 角色 ARN | 仅适用于 IAM 身份验证,即 IAM 角色的 ARN。您可以在 AWS 的 IAM 角色设置中找到它。 |
| 文件夹路径 | 您想要连接文件夹的路径。路径必须以存储桶名称开头,且不得包含要同步数据的子文件夹名称。 |
| 主对称密钥 | 用于管理客户端侧加密的可选设置。您可以连接到使用存储在 AWS 密钥管理服务中的客户主密钥或客户生成的 256 位 AES 格式的密钥加密的对象。请查看 Amazon 文档,以了解详细信息。 |
| 区域名称 | S3 服务的区域,例如 欧洲(爱尔兰)。有关区域名称的列表,请查看 CRM Analytics 中的 S3 区域名称。 |
| 区域名称 | Amazon 代码 |
|---|---|
| 美国东部(俄亥俄州) | us-east-2 |
| 美国东部(北弗吉尼亚州) | us-east-1 |
| 美国西部(北加利福尼亚州) | us-west-1 |
| 美国西部(俄勒冈州) | us-west-2 |
| 非洲(开普敦) | af-south-1 |
| 亚太地区(香港) | ap-east-1 |
| 亚太地区(孟买) | ap-south-1 |
| 亚太地区(大阪) | ap-northeast-3 |
| 亚太地区(首尔) | ap-northeast-2 |
| 亚太地区(新加坡) | ap-southeast-1 |
| 亚太地区(悉尼) | ap-southeast-2 |
| 亚太地区(东京) | ap-northeast-1 |
| 加拿大(中部) | ca-central-1 |
| 中国(北京) | cn-north-1 |
| 中国(宁夏) | cn-northwest-1 |
| 欧洲(法兰克福) | eu-central-1 |
| 欧洲(爱尔兰) | eu-west-1 |
| 欧洲(伦敦) | eu-west-2 |
| 欧洲(米兰) | eu-south-1 |
| 欧洲(巴黎) | eu-west-3 |
| 欧洲(斯德哥尔摩) | eu-north-1 |
| 中东(巴林) | me-south-1 |
| 南美(圣保罗) | sa-east-1 |
| AWS GovCloud(美国东部) | us-gov-east-1 |
| AWS GovCloud(美国西部) | us-gov-west-1 |
在使用 Amazon S3 连接器时,请谨记这些行为。
- 连接的对象名称必须以字母开头,并且只包含字母、数字或下划线。对象名不能以下划线结尾。
- 仅支持包含字母数字、点、下划线或破折号字符组合的字段名称。如果连接器中存在含有其他字符(例如空格或括号)的字段名称,则同步会失败。
- 连接器最多可以同步 1 亿行或每个对象 50 GB,以先达到的限制为准。 当使用连接器时,Salesforce Government Cloud 组织数据通过高级加密进行传输保护,对于每个连接的对象,可以同步多达 1000 万行或 5 GB,以先达到的限制为准。
- 为避免 Amazon S3 连接器设置超时,请选择少于 5000 个条目选项的文件夹路径。条目是您要同步的文件夹、文件夹中的文件以及所有子文件夹和子文件。推荐的最佳做法是在专用于数据同步的存储桶中创建一个存储桶或文件夹,仅填充要同步的文件。
- 每个连接最多可以支持 512 列。对于具有更多列的数据,拆分数据,创建多个连接,并使用模式组合数据集。
- 用双引号包围包含引号和逗号的字段。一些 CSV 生成器在需要时会自动给文本字段添加双引号,而另一些则不这样做。由于生成器行为不一致,我们建议您将所有文本字段用双引号括起来,以确保诸如“或”之类的字符不会导致数据同步问题。
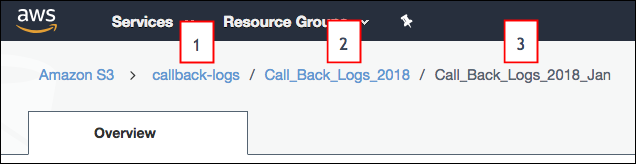
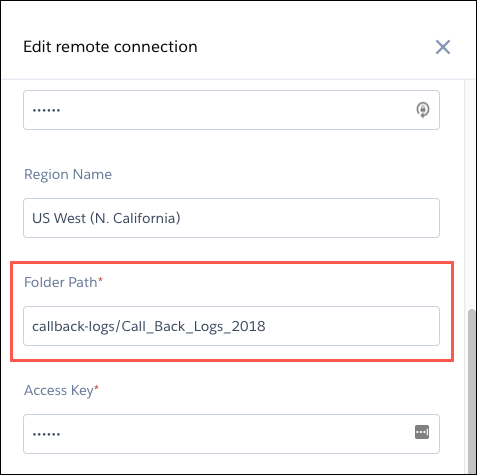
- 您在连接设置中指定的文件夹路径必须以存储桶名称和父文件夹开始。不要包含要连接的文件夹。我们来看一个示例。您想要在 S3 中从 Call_Back_Logs_2018_Jan 加载文件。文件夹路径将在您在 S3 中打开时显示在文件夹上方。S3 中的文件夹路径以存储器名称 (1) 开头,然后是文件夹名称 (2)。在此示例中,子文件夹 (3) 包含要同步的 CSV 数据。在指定此连接的文件夹路径设置时,您仅可包含存储桶 (1) 和父文件夹 (2),而非要同步的子文件夹 (3)。创建连接后,直接在父文件夹 (2) 下的所有子文件夹,包括 Call_Back_Logs_2018_Jan,将显示为您可以使用此连接同步的可能对象。
- S3 中的文件夹名称必须符合开发人员的命名约定,且不得包含空格或特殊字符。
- 复制子文件夹中的其中一个文件,并将其重命名为 schema_sample.csv。删除 schema_sample.csv 中的所有行,标题行和每列正确格式的一行示例数据除外。CRM Analytics 使用此文件检测 CSV 数据的模式,并且不从该文件导入任何数据。
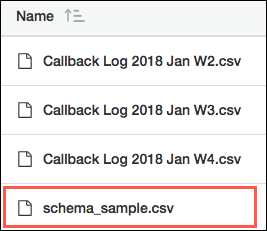
- 对于您想要从 S3 子文件夹加载的每个文件,其文件名必须以 .csv 结尾。每个文件也必须包含标题行,且字段与 schema_sample.csv 文件相同。文件可以包含其他字段,但这些字段不会加载。CRM Analytics 会忽略不满足这些要求的文件。
- 每个文件标题行中的文件名必须符合开发人员的命名约定,且不得包含空格或特殊字符。模式文件和数据文件中的标题行区分大小写,因此始终使用相同的大小写。
- 您仅可以加载整个文件,而非文件的一部分。
连接示例
为了更好地理解 S3 连接器在更复杂的场景下是如何工作的,请考虑 S3 中的以下层次结构。层次结构有两个存储桶:Quarterly_Financial_Data 和 Call_Logs。第一个存储桶有一个级别的文件夹。第二个存储桶有两个级别:父文件夹和子文件夹。以下是 S3 的层次结构。
- Quarterly_Financial_Data
- 2018
- 2018_quarter1_results.csv
- 2018_quarter2_results.csv
- 2018_quarter3_results.csv
- 2018_quarter4_results.csv
- 2019
- 2019_quarter1_results.csv
- 2019_quarter2_results.csv
- 2019_quarter3_results.csv
- 2019_quarter4_results.csv
- 2018
- Call_Logs
- 2018_Call_Logs
- Q1_2018
- call_logs_2018_01.csv
- call_logs_2018_02.csv
- call_logs_2018_03.csv
- Q2_2018
- call_logs_2018_04.csv
- call_logs_2018_05.csv
- call_logs_2018_06.csv
- Q3_2018
- call_logs_2018_07.csv
- call_logs_2018_08.csv
- call_logs_2018_09.csv
- Q4_2018
- call_logs_2018_10.csv
- call_logs_2018_11.csv
- call_logs_2018_12.csv
- Q1_2018
- 2018_Call_Logs
让我们看看如何设置连接和连接对象来实现以下目标。
| 目标 | 操作 |
|---|---|
| 将多个存储桶中的数据提取到 CRM Analytics 中。 | 因为每个连接都与单个存储桶相关联,所以为每个存储桶创建单独的连接。 例如,要从 Quarterly_Financial_Data 和 Call_Logs 存储桶中提取数据,请创建两个连接,一个用于 Quarterly_Financial_Data,另一个用于 Call_Logs。对于每个连接,在文件夹路径连接属性中设置适当的存储桶名称。 |
| 从父文件夹中提取特定文件夹,但不是所有子文件夹。 | 为父文件夹创建连接,然后使用该连接,连接到特定的子文件夹。 例如,要从 Q1_2018 和 Q2_2018 文件夹中提取呼叫日志,请使用文件夹路径 Call_Logs/2018_Call_Logs 创建连接。然后为 Q1_2018 和 Q2_2018 创建连接的对象。 |
| 从文件夹下的 CSV 文件子集提取数据。 | 将文件子集移动到子文件夹中,在父文件夹上创建连接,然后使用该连接,连接到子文件夹。 例如,要从 call_logs_2018_11.csv 和 call_logs_2018_12.csv 中提取数据,请将这些 CSV 文件移动到 Q4_2018 下的新子文件夹中。接下来,使用文件夹路径 Call_Logs/2018_Call_Logs/Q4_2018 创建连接。最后,基于新的子文件夹创建连接的对象。 |