In CRM Analytics, unlike a lookup, a join creates a separate record for each match in the
target dataset when multiple rows match. Before using a join, ensure that you understand the
implications of duplicate rows.
Required Editions
Available in Salesforce Classic and Lightning Experience.
Available with CRM Analytics, which is available for an extra cost in
Enterprise, Performance, and Unlimited Editions. Also available in
Developer Edition.
Review the following tips.
Don’t double count measures when aggregating records from a join.
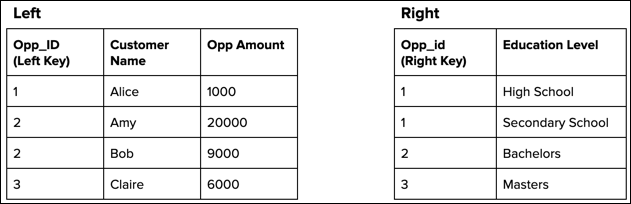
Consider the following two data streams that feed the recipe’s target dataset. Both input
data streams have duplicate key values.
A left join duplicates the Opp_ID 1 record in the left data stream because it has
multiple matches in the right data stream.
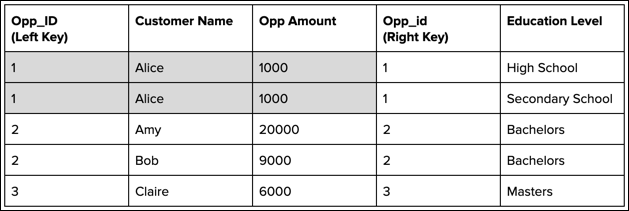
Notice that the duplicated records repeat the opportunity amount for Alice. If you added
all opportunity amounts to get the total, double count the amount for Alice. To prevent
duplicate records, use a lookup instead of a join.
Refrain from using joins when the join keys have a many-to-many relationship.
When the join keys have a many-to-many relationship, the target dataset can become
significantly larger than the input data streams. For instance, if four records on the
left and five records on the right have the same key value, the join adds 20 (4*5) records
to the target dataset. In a more extreme case, if 10,000 records on the left and 5,000 on
the right share a key value, the join creates 50 million records in the target
dataset.
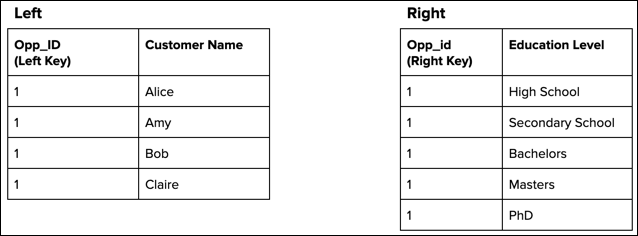
To illustrate why this occurs, consider the following two data streams that feed the
recipe’s target dataset. Both input data streams have duplicate key values.
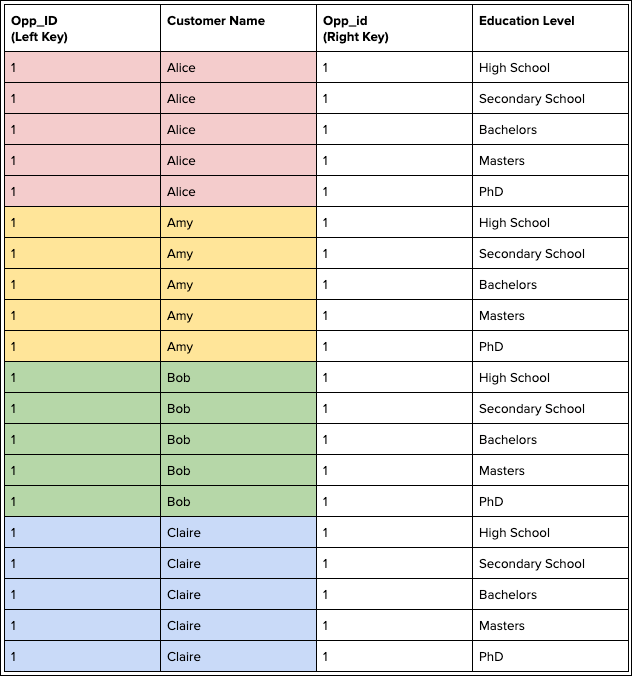
A left join duplicates each record in the left data stream five times because it has five
matches in the right data stream.
To prevent duplicate records, use a lookup instead of a join. If you must use a join, try
adding more key fields to make the keys have more unique values.
Did this article solve your issue?
Let us know so we can improve!
Loading
Salesforce Help | Article
Cookie Consent Manager
General Information
Required Cookies
Functional Cookies
Advertising Cookies
General Information
We use three kinds of cookies on our websites: required, functional, and advertising. You can choose whether functional and advertising cookies apply. Click on the different cookie categories to find out more about each category and to change the default settings.
Privacy Statement
Required Cookies
Always Active
Required cookies are necessary for basic website functionality. Some examples include: session cookies needed to transmit the website, authentication cookies, and security cookies.
Functional Cookies
Functional cookies enhance functions, performance, and services on the website. Some examples include: cookies used to analyze site traffic, cookies used for market research, and cookies used to display advertising that is not directed to a particular individual.
Advertising Cookies
Advertising cookies track activity across websites in order to understand a viewer’s interests, and direct them specific marketing. Some examples include: cookies used for remarketing, or interest-based advertising.