
You are here:
Columns and Rows in Datasets
A dataset is analogous to a table in a database. It organizes data by columns and rows.
A dataset stores data in a file storage system, where data is organized by strings (dimensions) and numbers (measures). To make it easier to visualize, you can think of a dataset as a table, where the fields are columns and the values are rows.
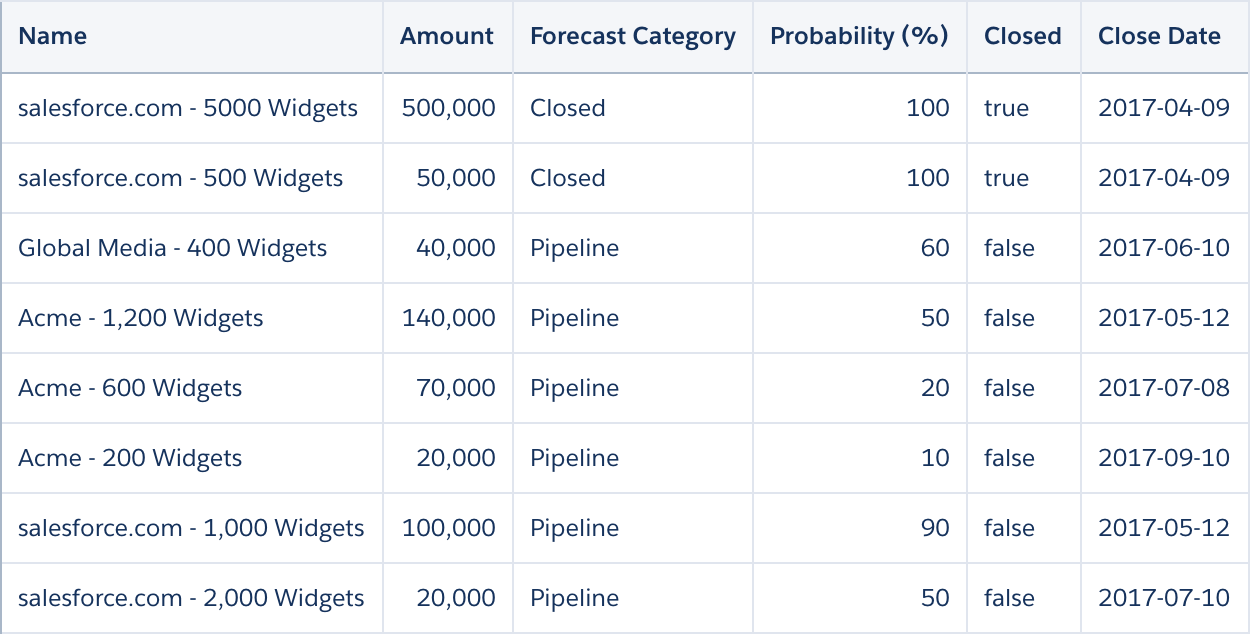
Note In a dataset, columns are analogous to fields in Salesforce objects and rows are analogous
to records. However, when talking about datasets, we always use the terms column and
row.
- A column represents a category of information, such as an opportunity source or account name. Each column has a name, a data type, and other properties.
- A row represents an instance of data in the dataset. Rows can contain transactional data, such as individual invoices, or they can contain summary data, such as weekly invoice totals. What’s important is that rows in a dataset must contain the same level of granularity, such as all invoice transactions or all weekly totals, rather than mixed levels.
Did this article solve your issue?
Let us know so we can improve!