
You are here:
Binary Classification Metrics
Metrics for binary classification help evaluate the performance of a model that categorizes data into two classes.
Accuracy
In addition to the overall accuracy score using AUC, there are two additional metrics for understanding the accuracy of a binary classification model.
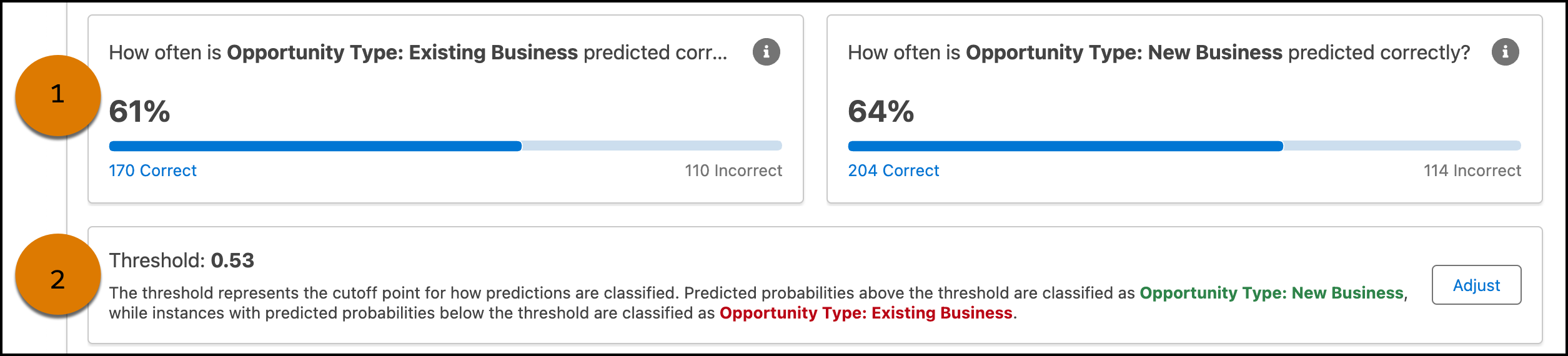
View how often the model makes correct and incorrect predictions (1). See the threshold cutoff point for how predictions are classified between classes (2).
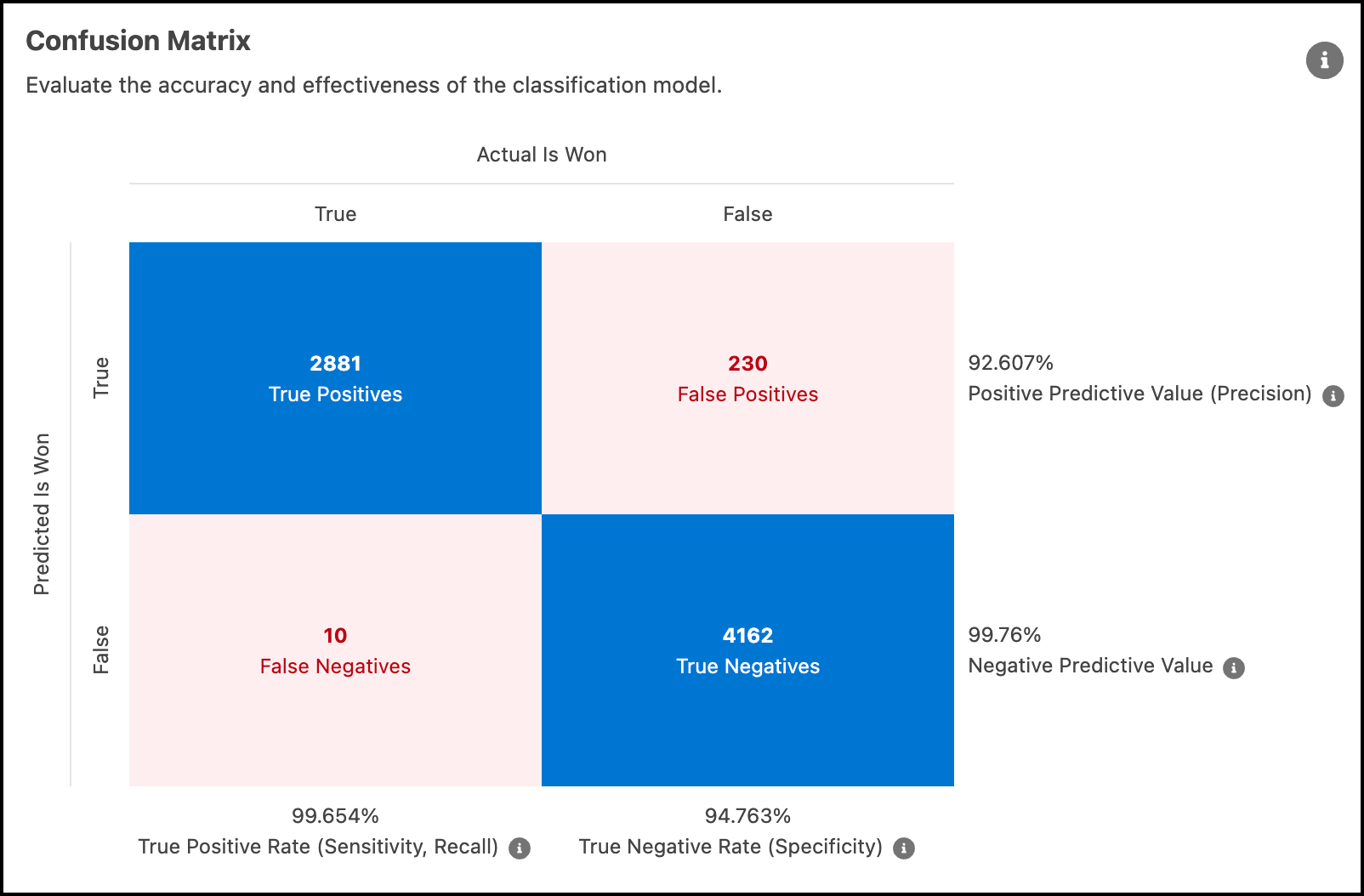
Confusion Matrix
Use the confusion matrix to evaluate the tradeoffs between different error types based on the threshold value. The chart displays how many times the model correctly and incorrectly classifies observations at the associated threshold.
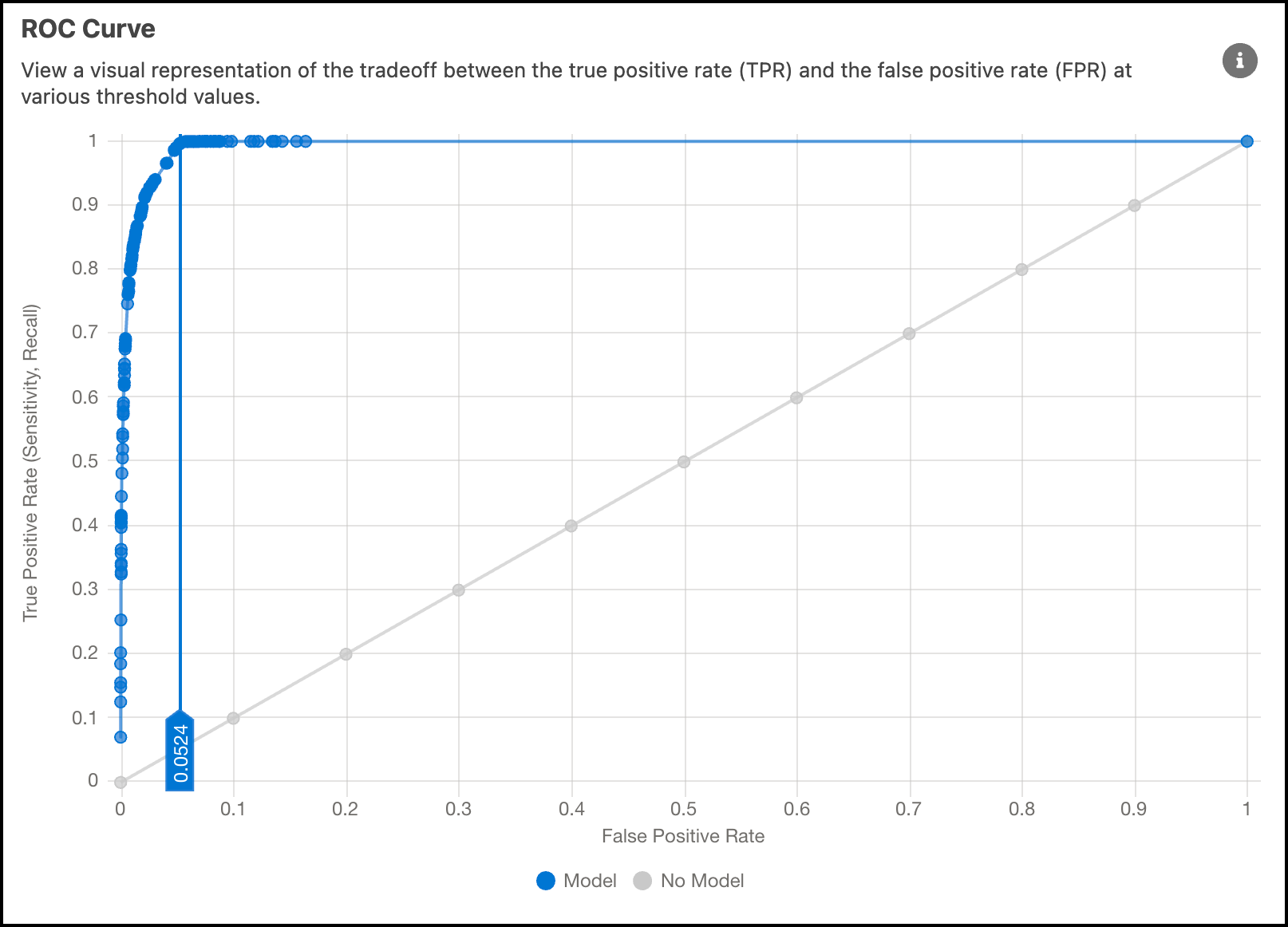
ROC Curve
The Receiver Operating Characteristic (ROC) curve displays the performance measurement at various threshold settings. ROC is a probability curve and AUC (Area Under the Curve) quantifies the degree of separability. Use the chart to see how effectively the model can differentiate between classes.
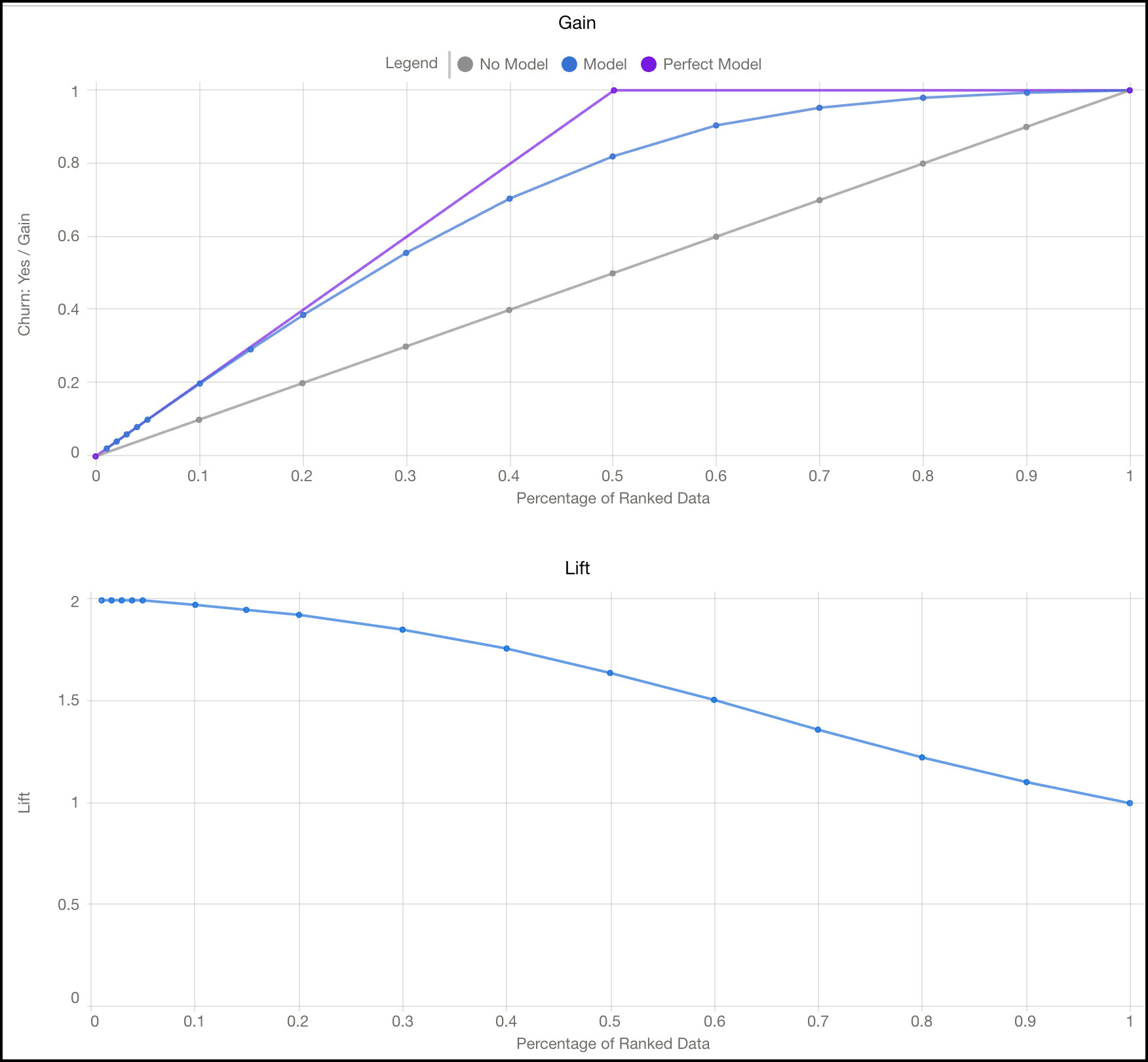
Gain and Lift
Gain and Lift charts show the benefit of the model. Using a portion of the data that’s scored and ranked for analysis, the charts measure results obtained with the model compared to random guessing without a model. The greater the gain and the higher the lift, the more effective the model.
| Chart | Description |
|---|---|
| Gain | The gain chart plots the total positive rate, or gain, by percentage of the data. The closer the model line is to theoretical exactness (perfect model) and the further it is from random guessing (no model), the greater the gain. Gain can be used to prioritize your organization’s resources. For example, if a model has 80% gain at 20% of the data, then 80% of the target can be reached with the top 20% of the data. |
| Lift | The lift chart plots the improvement ratio, or lift, by percentage of the data. Better models have higher lifts. For example, if a model has 2.5 lift at 20% of the data, then results with the model are 2.5 times better in the top 20% of the data than without. |
4-Fold Cross Validation Results
The 4-fold cross-validation approach mitigates sampling bias during the model validation process. In this method, the data is randomly divided into four separate partitions of equal size, and the model undergoes four test passes (folds). During each pass, three partitions serve as the training data, while the remaining one serves as the test data. By completing four test passes, each partition is used once as the validation data and three times as part of the training data, ensuring a comprehensive evaluation. Refer to the table of validation results to examine metrics corresponding to each fold of the data.
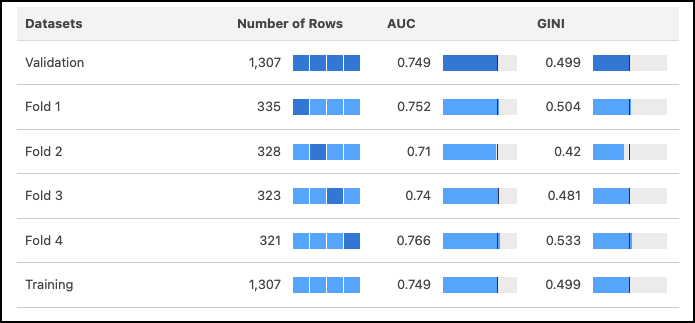
| Metric | Description |
|---|---|
| Number of records | Total number of observations. The meaning of a value varies per column.
|
| AUC | The Area Under the Curve (AUC) represents the rate of correct classification by a logistic model.
|
| GINI | The Gini Index quantifies how closely this logistic model performs to a theoretically best possible model. |
Other Metrics
Consider other metrics that are commonly used to evaluate model quality.
| Metric | Description |
|---|---|
| Accuracy | Accuracy measures the proportion of outcomes that the model predicted correctly (true positives and true negatives).
|
| F1 Score | F1 score is the harmonic average of the positive predictive value (precision) and the true positive rate (recall).
|
| False Negatives | The number of predicted negatives that are actually positive. |
| False Negative Rate | False Negative Rate (FNR, also called type II error or miss rate) is the proportion of predicted false negatives among all the actual positives.
|
| False Positives | The number of predicted positives that are actually negative. |
| False Positive Rate | False Positive Rate (FPR, also called type I error, false alarm ratio, or fallout) is the number of predicted false positives among all the actual negatives.
|
| Informedness | Informedness (also called Youden's J statistic) measures how well the model predicts both positives and negatives.
|
| Markedness | Markedness measures the trustworthiness of positive and negative predictions by the model.
|
| MCC | The Matthews Correlation Coefficient (MCC) provides a more even representation of the four parts of the confusion matrix than other metrics.
|
| Negative Predictive Value | Negative Predictive Value (NPV) is the proportion of actual negatives among all the predicted negatives.
|
| Positive Predictive Value (Precision) | Positive Predictive Value (PPV, also called precision) is the proportion of actual positives among all the predicted positives.
|
| True Negatives | The number of predicted negatives that are actually negative. |
| True Negative Rate (Specificity) | True Negative Rate (TNR, also called specificity) is the proportion of predicted negatives among all the actual negatives.
|
| True Positives | The number of predicted positives that are actually positives. |
| True Positive Rate (Sensitivity, Recall) | True Positive Rate (TPR, also called sensitivity or recall) is the proportion of predicted positives among all the actual positives.
|