您在此处:
二元分类度量
二元分类的度量有助于评估将数据分为两类的模型的性能。
准确性
除了使用 AUC 的总体准确性分数之外,还有两个额外的度量来理解二元分类模型的准确性。
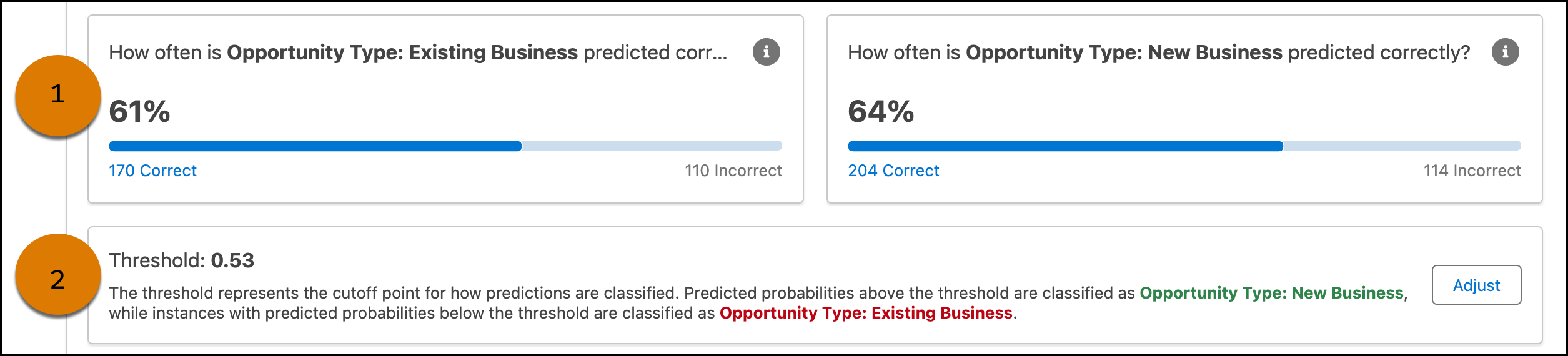
查看模型做出正确和错误预测的频率 (1)。请查看阈值截止点,了解预测如何在类之间分类 (2)。
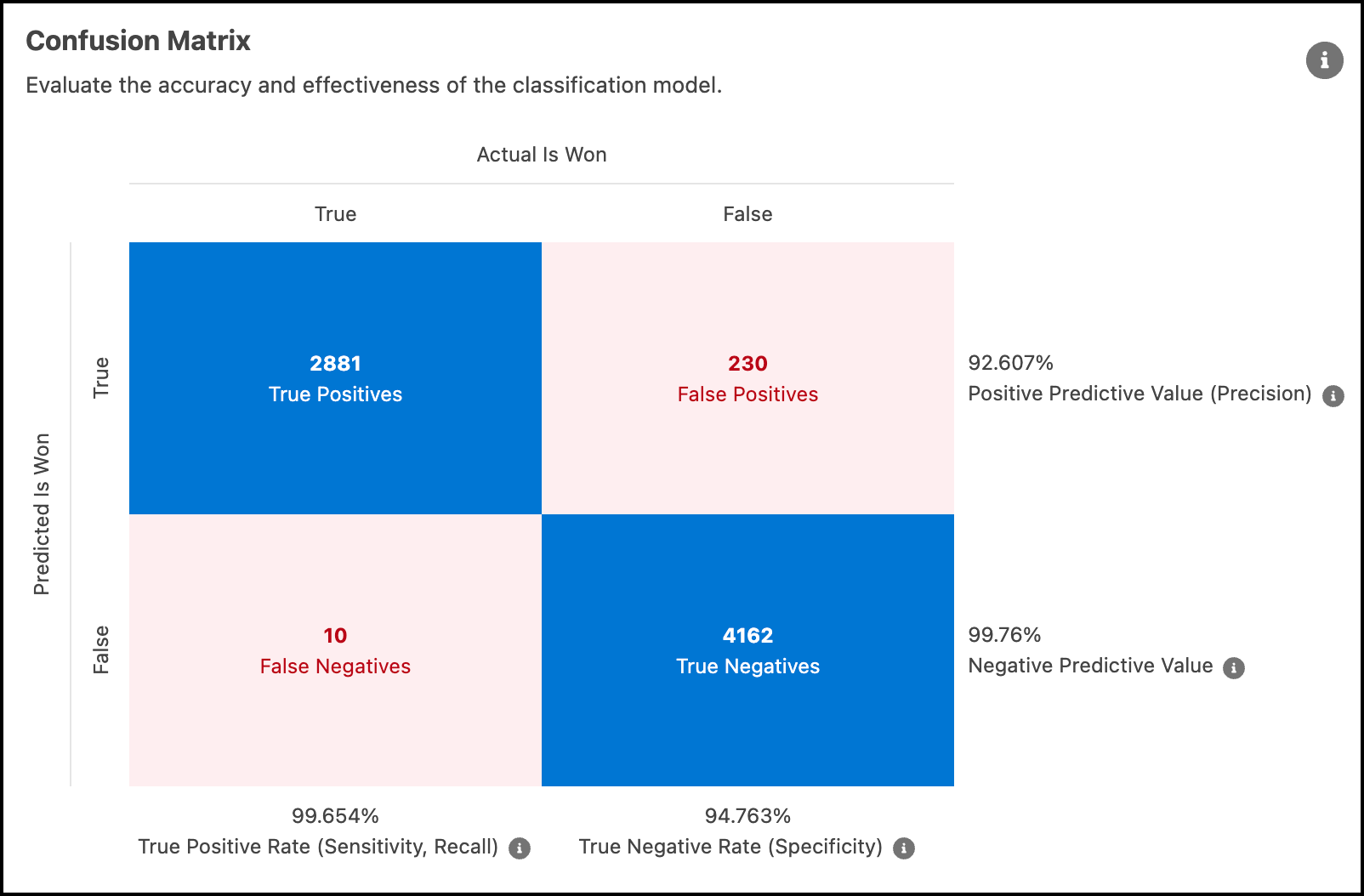
混淆矩阵
使用混淆矩阵来评估基于阈值的不同错误类型之间的权衡。该图表显示了模型在相关阈值下对观察值进行正确和错误分类的次数。
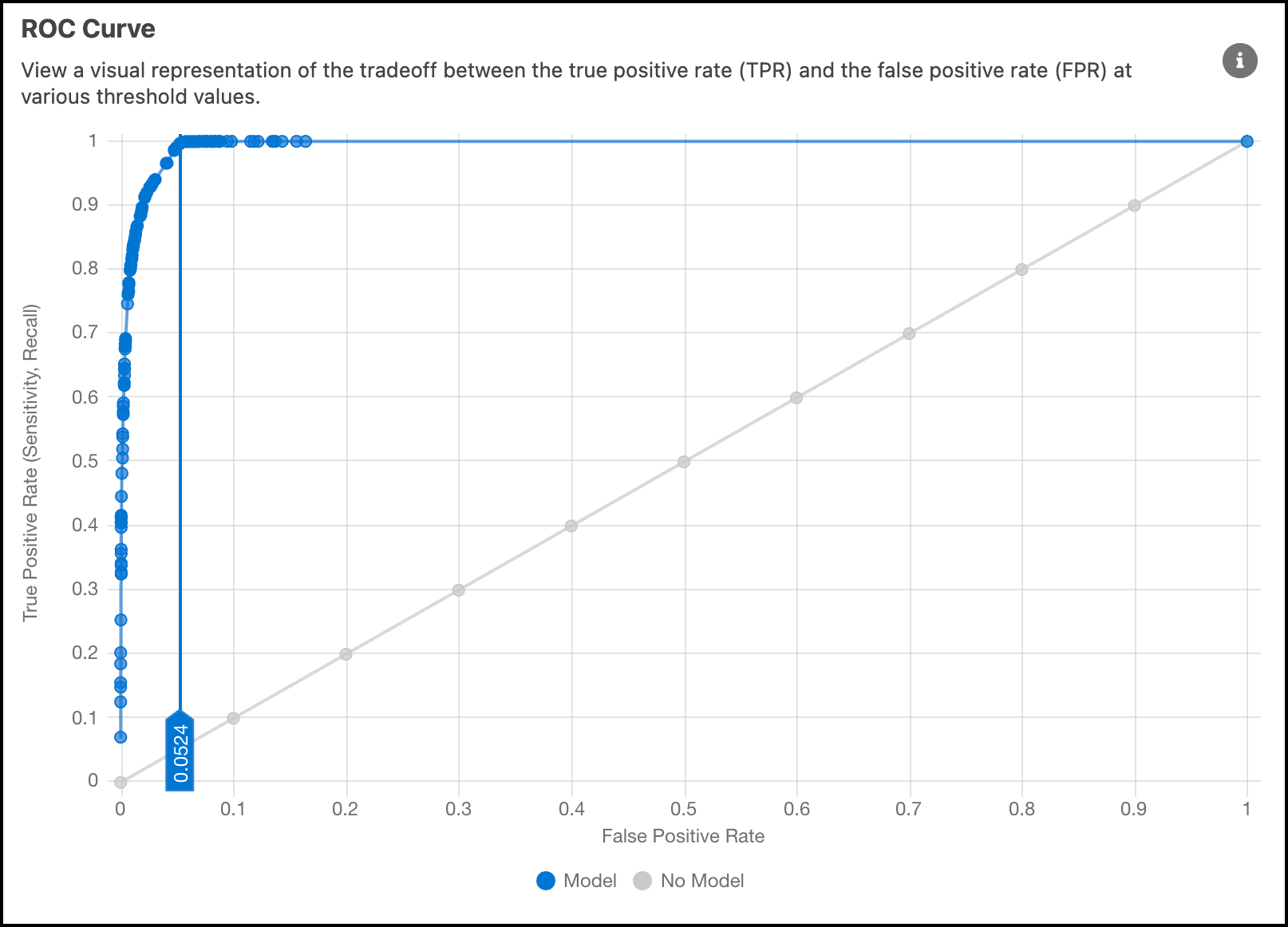
ROC 曲线
接收器工作特性 (ROC) 曲线显示不同阈值设置下的性能测量。ROC 是概率曲线,AUC(曲线下面积)量化了可分性的程度。使用该图表查看模型如何有效地区分类。
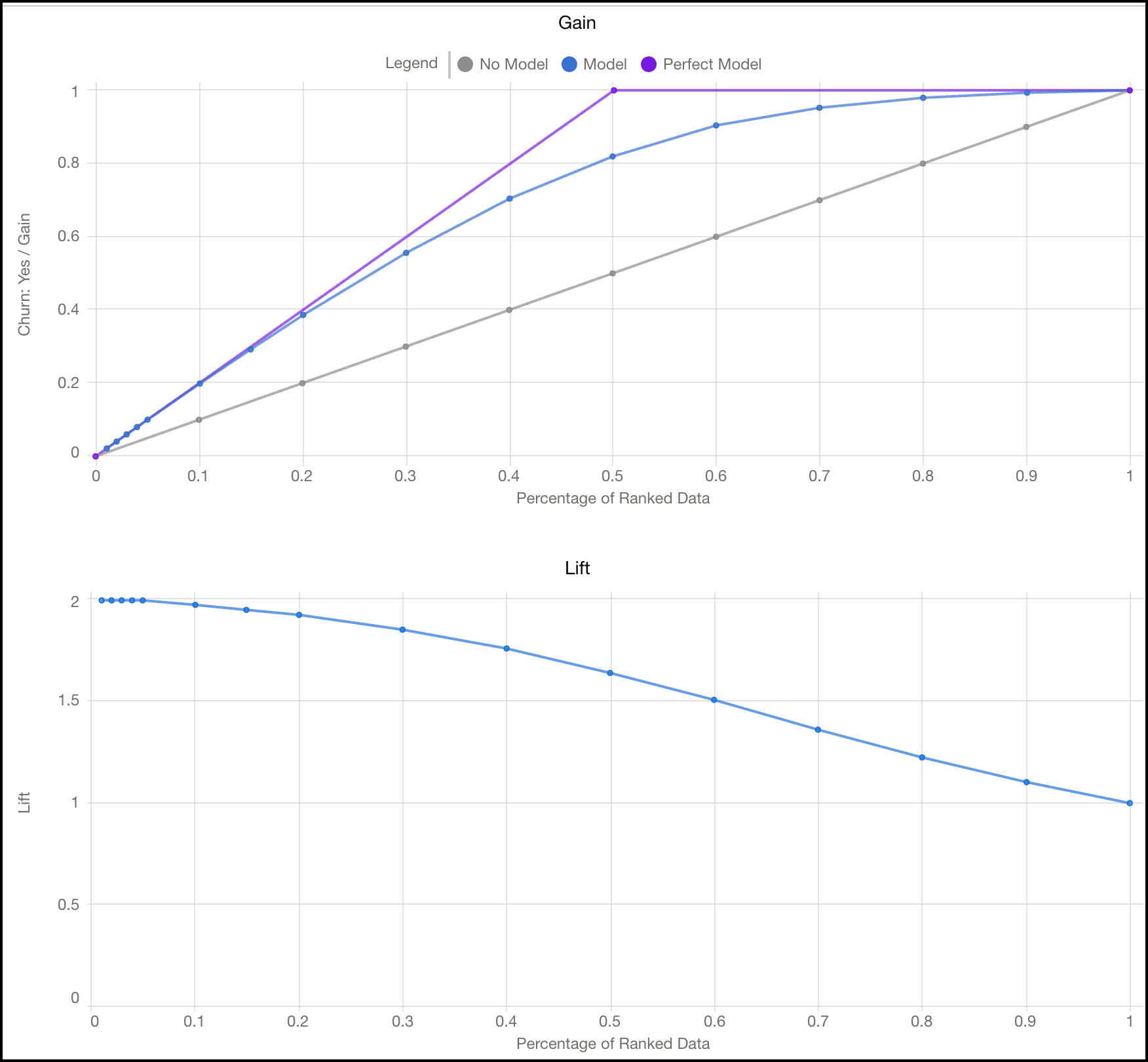
收益和提升
收益和提升图表显示了模型的益处。通过使用部分数据进行评分和排序以进行分析,图表测量了使用模型获得的结果与不使用模型的随机猜测的结果。收益越大,提升越高,模型就越有效。
| 图表 | 描述 |
|---|---|
| 收益 | 收益图按数据的百分比绘制总正比率或收益。模型线越接近理论精确度(完美模型),离随机猜测越远(无模型),收益越大。收益可用于确定组织的资源优先级。 例如,如果一个模型在 20% 的数据上有 80% 的收益,那么用前 20% 的数据就可以达到 80% 的目标。 |
| 提升 | 提升图按数据的百分比绘制改善率或提升。更好的模型具有更高的提升。 例如,如果一个模型在 20% 的数据中具有 2.5 的提升,那么在数据的前 20% 中使用该模型时,获得的结果比不使用该模型时获得的结果好 2.5 倍。 |
4 倍交叉验证结果
4 倍交叉验证方法减轻了模型验证过程中的采样偏差。在这种方法中,数据被随机分成大小相等的四个独立分区,模型经历四次测试(倍)。在每一次测试中,三个分区用作训练数据,而剩下的一个用作测试数据。通过完成四次测试,每个分区一次用作验证数据,三次用作训练数据的一部分,从而确保全面的评估。参考验证结果表,检查与数据的每个倍数相对应的指标。
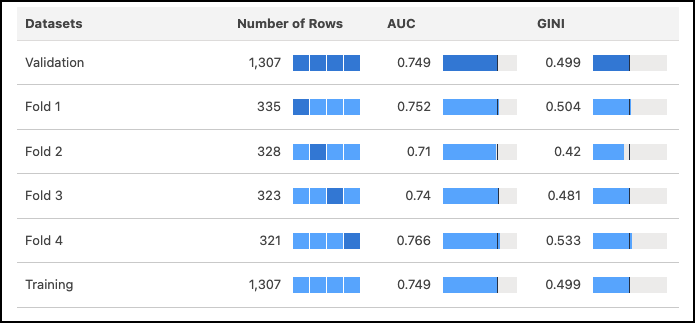
| 度量 | 描述 |
|---|---|
| 记录数 | 观察总数。值的含义因列而异。
|
| AUC | 曲线下面积 (AUC) 代表逻辑模型的正确分类率。
|
| GINI | Gini 指数量化了这种逻辑模型与理论上最佳模型的接近程度。 |
其他度量
考虑通常用于评估模型质量的其他度量。
| 度量 | 描述 |
|---|---|
| 准确性 | 准确性衡量模型正确预测结果的比例(真阳性和真阴性)。
|
| F1 分数 | F1 分数是阳性预测值(精度)和真阳性率(召回)的和谐平均值。
|
| 假阴性 | 实际为正的预测负数。 |
| 假阴性率 | 假阴性率 (FNR,也称为 II 型错误或漏报率) 是预测假阴性在所有实际阳性中的比例。
|
| 假阳性 | 实际为负的预测阳性的数量。 |
| 假阳性率 | 假阳性率(FPR,也称为类型 I 误差、假警报率或影响)是所有实际阴性中预测的假阳性的数量。
|
| 表达性 | 知情性(也称为 Youden 的 J 统计)衡量模型预测积极和消极因素的程度。
|
| 标记性 | 标记性 衡量模型对积极和消极预测的信任度。
|
| MCC | 与其他度量相比,对于混淆矩阵的四个部分,Matthews 相关系数 (MCC) 提供更均匀的表征。
|
| 负预测值 | 负预测值 (NPV) 是实际负值在所有预测负值中的比例。
|
| 正预测值(精度) | 阳性预测值 (PPV,也称为精度) 是实际阳性在所有预测阳性中的比例。
|
| 真阴性 | 实际为负的预测负数。 |
| 真阴性率(特异性) | 真阴性率 (TNR,也称为特异性) 是预测阴性在所有实际阴性中的比例。
|
| 真阳性 | 实际为阳性的预测阳性的数量。 |
| 真阳性率(灵敏度、召回) | 真阳性率(TPR,也称为敏感性或召回)是预测阳性在所有实际阳性中的比例。
|