
You are here:
Cross Join
In Salesforce Data Pipelines, a cross join combines unrelated records and includes all rows from the left (recipe data) and the right. Unlike other joins that use keys to find matches, the cross join pairs every row from one dataset with every row of another dataset (known as the Cartesian Product).
- 10,000-row dataset (left) with a 1,000-row dataset (right)
- 20,000-row dataset (left) with a 500-row dataset (right)
- 40,000-row dataset (left) with a 250-row dataset (right)
- 100,000-row dataset (left) with a 100-row dataset (right)
Example
A company sells products at various locations. To assist with stock tracking, use a cross join to combine the product and store datasets to find all the possible pairs of product and store.
Consider the following two data streams that feed the recipe’s target dataset. To illustrate how this join combines unrelated records, row number is included for reference but isn’t needed in the data.
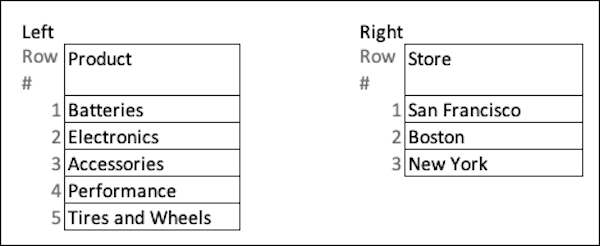
After performing the cross join, the recipe produces this target dataset.
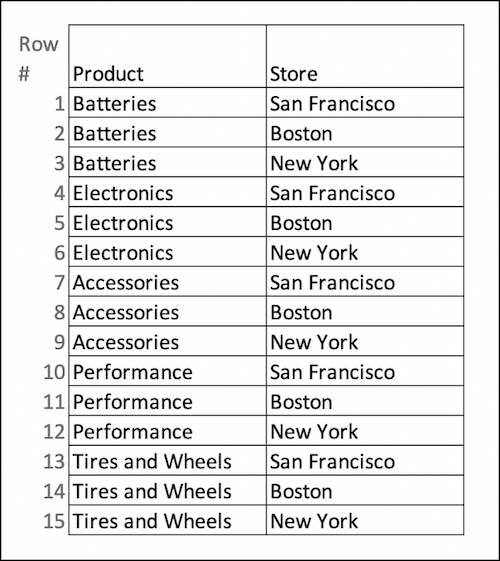
Because a cross join creates a larger dataset than either of the source datasets, it has some limitations. Keep these points in mind when designing and testing your cross join.
- Only one cross join per recipe
- Cross join results maximum of 10 million
- Left dataset column maximum of 8 and row maximum of 100,000
- Right dataset column maximum of 8 and row maximum of 1,000
- Doesn’t support mulit-value columns