
You are here:
Inner Join
In Salesforce Data Pipelines, an inner join includes only matching rows from the left (recipe data) and right. The join includes all matched rows in the target when multiple rows match.
Example
Our company's marketing team captures demographic data in an external data source for opportunities stored in Salesforce. To compare opportunities by education level of the customer, let’s first combine both sets of data into a dataset using an inner join.
Consider the following two data streams that feed the recipe’s target dataset. To illustrate how this recipe function handles unmatched rows and duplicate keys, we included them in both data streams.
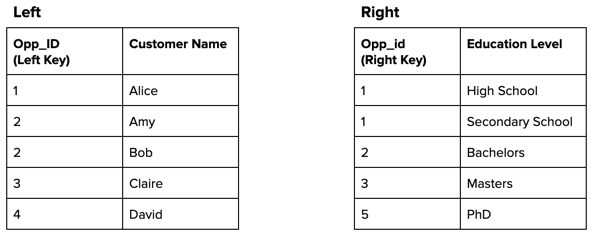
After performing the inner join based on the matching keys, the recipe produces the following target dataset.
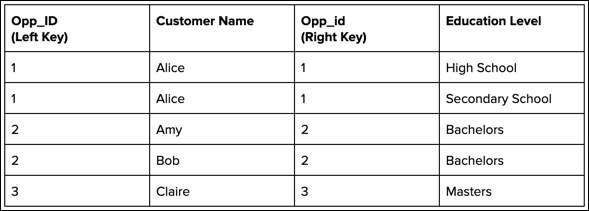
All rows that have a match are included in the target. Because of multiple matches, you see two records with Opp_ID 2 (Amy and Bob) and two records with Opp_id 1 (High School and Secondary School). Notice also that Opp_ID 4 and Opp_id 5 are excluded from the target because neither have a match.