
詳細情報:
Amazon S3 接続
S3 バケットの CSV データを CRM Analytics と同期させるには、Amazon S3 コネクタを使用してリモート接続を作成します。
接続の詳細
このコネクタの接続を設定する場合、S3 バケットのフォルダー階層を把握することが重要です。接続の作成時に S3 バケット設定と親のフォルダーパスを設定します。次に、親のフォルダーパスのサブフォルダーで、CRM Analytics と同期する CSV ファイルが含まれる 1 つ以上のオブジェクトを選択します。接続済みオブジェクトを同期すると、CRM Analytics は schema_sample.csv という CSV ファイルを検索して、フォルダー内の CSV データのスキーマを検出し、データのプレビューを表示します。ただし、schema_sample.csv ファイルからデータはインポートされません。このプレビューから、フォルダーから読み込んでいるすべてのファイルの項目属性を表示および変更できます。
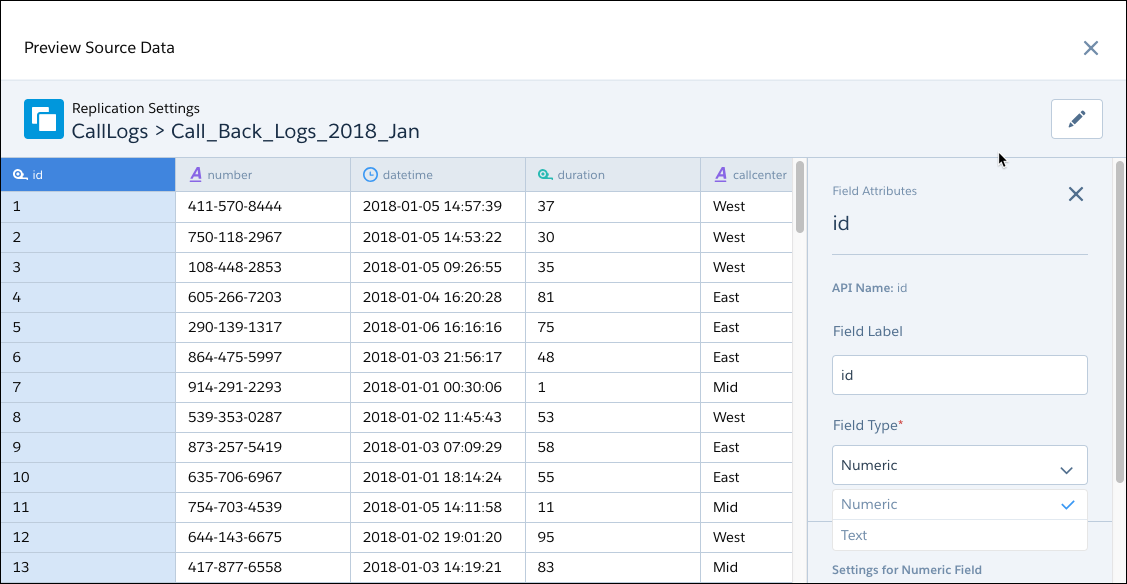
CRM Analytics は schema_sample.csv を使用して使用可能なフィールドを派生するため、必要なフィールドを選択できます。次に、コネクタはサブフォルダーで選択した項目セットに一致する CSV ファイルを読み込み、1 つのオブジェクトに行を追加します。
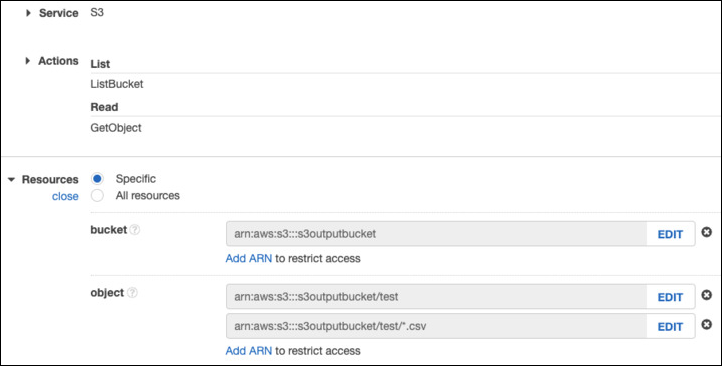
この接続の作成に使用される Amazon S3 アカウントの権限には、ListBucket および GetObject が含まれている必要があります。権限には、バケットと「任意のオブジェクト」または (特定のオブジェクトに限定する場合は) 参照されるパスとオブジェクトを表す適切な ARN へのリソース付与権が含まれている必要があります。次に例を示します。
接続の作成
- [データマネージャー接続] タブで、[新しい接続] をクリックします。
- コネクタの名前をクリックし、[次へ] をクリックします。
- コネクタ設定を入力します。
- 設定を検証してソースへの接続を試みるには、[保存 & テスト] をクリックします。接続に失敗すると、考えられる理由が CRM Analytics に表示されます。
特に明記されていない限り、すべての設定で値が必要です。
| 設定 | 説明 |
|---|---|
| 接続名 | 接続を識別します。異なる接続を区別しやすい規則を使用します。 |
| API 参照名 | 接続の API 参照名。この名前にスペースを含めることはできません。API 参照名は、この接続を介して抽出されたデータをレシピで参照するために使用します。接続の作成後に API 参照名を変更することはできません。 |
| Description (説明) | 接続の説明。 |
| 認証種別 | 標準認証の場合、「Root」と入力します。AWS IAM(Identity Access Management)認証の場合、「IAM」と入力します。AWS データに詳細にアクセスするには、IAM 認証を使用して、AWS で IAM ユーザーとロールを設定します。AWS IAM についての詳細は、「AWS での IAM の使用開始」を参照してください。 |
| Access Key (アクセスキー) | Amazon S3 バケットのアクセスキー ID。 |
| Secret Key (秘密鍵) | Amazon の秘密のアクセスキー。 |
| AWS ロール ARN | IAM 認証の場合のみ、IAM ロールの ARN。これは、AWS の [IAM ロールの設定] にあります。 |
| Folder Path (フォルダーパス) | 接続先のフォルダーへのパス。パスはバケット名で始まる必要があり、データを同期するサブフォルダーの名前を含むことはできません。 |
| Master Symmetric Key (マスター対象鍵) | クライアント側暗号化を管理するための省略可能な設定。AWS Key Management Service に保存されているお客様の主鍵、または 256 ビットの AES 形式でお客様が生成した鍵で暗号化されたオブジェクトに接続できます。詳細は、Amazon のドキュメントを参照してください。 |
| Region Name (リージョン名) | S3 サービスのリージョン (例: EU (アイルランド))。リージョン名のリストについては、以下の「CRM Analytics の Amazon リージョン名」を参照してください。 |
| リージョン名 | Amazon コード |
|---|---|
| 米国東部 (オハイオ) | us-east-2 |
| 米国東部 (バージニア北部) | us-east-1 |
| 米国西部 (北カリフォルニア) | us-west-1 |
| 米国西部 (オレゴン) | us-west-2 |
| アフリカ (ケープタウン) | af-south-1 |
| アジア太平洋 (香港) | ap-east-1 |
| アジア太平洋 (ムンバイ) | ap-south-1 |
| アジア太平洋 (大阪) | ap-northeast-3 |
| アジア太平洋 (ソウル) | ap-northeast-2 |
| アジア太平洋 (シンガポール) | ap-southeast-1 |
| アジア太平洋 (シドニー) | ap-southeast-2 |
| アジア太平洋 (東京) | ap-northeast-1 |
| カナダ (中部) | ca-central-1 |
| 中国 (北京) | cn-north-1 |
| 中国 (寧夏) | cn-northwest-1 |
| EU (フランクフルト) | eu-central-1 |
| EU (アイルランド) | eu-west-1 |
| EU (ロンドン) | eu-west-2 |
| 欧州 (ミラノ) | eu-south-1 |
| EU (パリ) | eu-west-3 |
| EU (ストックホルム) | eu-north-1 |
| 中東 (バーレーン) | me-south-1 |
| 南米 (サンパウロ) | sa-east-1 |
| AWS GovCloud (米国東部) | us-gov-east-1 |
| AWS GovCloud (米国西部) | us-gov-west-1 |
Amazon S3 コネクタを使用するときは、次の点に留意してください。
- 接続済みオブジェクト名は、先頭が文字で、文字、数字、またはアンダースコアのみが含まれている必要があります。オブジェクト名の末尾をアンダースコアにすることはできません。
- 英数字、ドット、アンダースコア、ダッシュの文字を組み合わせた項目名のみがサポートされます。コネクタに、スペースや括弧などの他の文字を含んだ項目名がある場合、同期に失敗します。
- コネクタは、オブジェクトあたり最大 1 億行または 50 GB のいずれか先に制限に達したものを同期できます。 このコネクタを使用する場合、Salesforce Government Cloud 組織のデータは高度な暗号化を使用して転送中に保護され、接続済みオブジェクトごとに最大 1,000 万行または 5 GB のいずれか先に制限に達したものを同期できます。
- Amazon S3 コネクタの設定タイムアウトを回避するには、エントリオプションが 5,000 未満のフォルダーパスを選択します。エントリには、同期するフォルダー、フォルダー内のファイル、およびすべてのサブフォルダーとサブファイルが含まれます。推奨されるベストプラクティスは、同期するファイルのみが含まれるバケットまたはバケット内のフォルダーをデータ同期専用に作成することです。
- 各接続では、最大 512 列をサポートできます。列数が多いデータの場合、データを分割して複数の接続を作成し、レシピを使用してデータセットを結合します。
- 引用符とカンマが含まれる項目は二重引用符で囲みます。必要に応じてテキスト項目が自動的に二重引用符で囲まれる CSV ジェネレーターもありますが、それ以外の CSV ジェネレーターもあります。ジェネレーターの動作が一貫していないため、すべてのテキスト項目を二重引用符で囲み、「'」や「,」などの文字によってデータ同期の問題が発生しないようにすることをお勧めします。
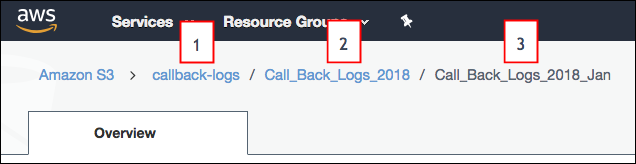
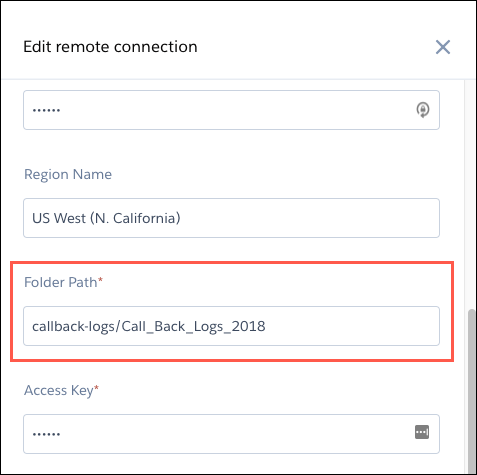
- 接続設定で指定したフォルダーパスは、バケット名と親フォルダーで始まる必要があります。接続するフォルダーは含めないでください。例を見てみましょう。S3 の Call_Back_Logs_2018_Jan からファイルを読み込みます。S3 で開くと、フォルダの上にフォルダ パスが表示されます。S3 のフォルダ パスはバケット名 (1) で始まり、フォルダ名 (2) が続きます。この例では、サブフォルダー (3) に同期する CSV データが含まれています。この接続のフォルダーパス設定を指定するときに、バケット (1) と親フォルダー (2) のみを含め、同期するサブフォルダー (3) は含めません。接続を作成すると、親フォルダ (2) の直下にあるすべてのサブフォルダ (Call_Back_Logs_2018_Jan を含む) が、この接続を使用して同期できるオブジェクトとして表示されます。
- S3 のフォルダー名は API 参照名の命名規則に従う必要があり、スペースや特殊文字を含めることはできません。
- サブフォルダーのいずれかのファイルの名前を schema_sample.csv に変更します。schema_sample.csv のヘッダー行と、各列に正しい形式のサンプルデータの 1 行を除くすべての行を削除します。CRM Analytics はこのファイルを使用して CSV データのスキーマを検出し、このファイルからデータをインポートしません。
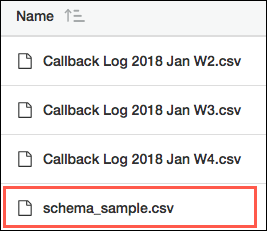
- S3 サブフォルダーから読み込む各ファイル名は、.csv で終了する必要があります。各ファイルには、ヘッダー行および schema_sample.csv ファイルと同じ項目が含まれる必要があります。ファイルに追加項目があっても問題ありませんが、それらの項目は読み込まれません。CRM Analytics は、これらの要件を満たさないファイルを無視します。
- 各ファイルのヘッダー行の項目名は API 参照名の命名規則に従う必要があり、スペースや特殊文字を含めることはできません。スキーマファイルとデータファイルのヘッダー行は大文字と小文字が区別されるため、大文字と小文字の使い分けを統一してください。
- 読み込めるのはファイル全体のみで、ファイルの一部は読み込めません。
接続の例
より複雑なシナリオでの S3 コネクタのしくみに関する理解を深めるため、S3 の次の階層を考えてみます。 この階層には Quarterly_Financial_Data と Call_Logs の 2 つのバケットがあります。最初のバケットには、1 レベルのフォルダーがあります。2 番目のバケットには、親フォルダーとサブフォルダーの 2 つのレベルがあります。この S3 階層は次のとおりです。
- Quarterly_Financial_Data
- 2018
- 2018_quarter1_results.csv
- 2018_quarter2_results.csv
- 2018_quarter3_results.csv
- 2018_quarter4_results.csv
- 2019
- 2019_quarter1_results.csv
- 2019_quarter2_results.csv
- 2019_quarter3_results.csv
- 2019_quarter4_results.csv
- 2018
- Call_Logs
- 2018_Call_Logs
- Q1_2018
- call_logs_2018_01.csv
- call_logs_2018_02.csv
- call_logs_2018_03.csv
- Q2_2018
- call_logs_2018_04.csv
- call_logs_2018_05.csv
- call_logs_2018_06.csv
- Q3_2018
- call_logs_2018_07.csv
- call_logs_2018_08.csv
- call_logs_2018_09.csv
- Q4_2018
- call_logs_2018_10.csv
- call_logs_2018_11.csv
- call_logs_2018_12.csv
- Q1_2018
- 2018_Call_Logs
コネクタと接続済みオブジェクトを設定し、次の目標を達成する方法を見てみましょう。
| 目標 | アクション |
|---|---|
| 複数のバケットからデータを CRM Analytics に抽出する。 | 各接続は 1 つのバケットに関連付けられているため、各バケットに個別の接続を作成します。 たとえば、Quarterly_Financial_Data と Call_Logs バケットからデータを抽出するには、Quarterly_Financial_Data 用に 1 つ、Call_Logs 用に 1 つの合計 2 つの接続を作成します。各接続の [Folder Path (フォルダーパス)] 接続プロパティで、適切なバケット名を設定します。 |
| 親フォルダーから、すべてのサブフォルダーではなく特定のフォルダーを抽出する。 | 親フォルダーの接続を作成し、その接続を使用して特定のサブフォルダーに接続します。 たとえば、Q1_2018 フォルダーと Q2_2018 フォルダーから活動ログを抽出するには、フォルダーパス Call_Logs/2018_Call_Logs を使用して 1 つの接続を作成します。次に、Q1_2018 と Q2_2018 の接続済みオブジェクトを作成します。 |
| フォルダー内にある CSV ファイルのサブセットからデータを抽出する。 | ファイルのサブセットをサブフォルダーに移動し、親フォルダーで接続を作成してから、その接続を使用してサブフォルダーに接続します。 たとえば、call_logs_2018_11.csv と call_logs_2018_12.csv からデータを抽出するには、これらの CSV ファイルを Q4_2018 の下位の新しいサブフォルダー内に移動します。 次に、フォルダーパス Call_Logs/2018_Call_Logs/Q4_2018 を使用して接続を作成します。最後に、新しいサブフォルダーに基づいて接続済みオブジェクトを作成します。 |