
詳細情報:
チャンク戦略
Data 360 では、いくつかのチャンク戦略がサポートされています。Data 360 では、使用しているコンテンツタイプに基づいて最適なチャンク戦略が自動的に選択されます。
たとえば、最も関連性の高いコンテキストと意味を提供する項目、それらの項目を分割する方法、取得した結果がEinstein Gen AI、自動化、分析アプリケーションでどのように使用されるかを検討します。たとえば、パス抽出戦略を使用して Knowledge 記事 DMO のカスタム テキスト フィールドを分割し、Knowledge オブジェクト間で検索するときに意味的に類似する結果を簡単に返すことができます。
セクション対応チャンク
セクション対応チャンクでは、タイトル要素とヘッダー要素を使用してドキュメントをチャンクします。セクションタイトルまたはヘッダー要素の下にあるすべてのテキストは、Data 360 で新しいセクションタイトルまたはヘッダー要素が検出されるまで、まとめてチャンクされます。これにより、文書の構造に基づいてコンテンツを一貫したセクションに分割できます。
セクションが任意に分割されることはありません。チャンクは常に自然なコンテンツの境界を尊重し、読みやすさとコンテキストを維持します。短いパラグラフやリスト項目がスタンドアロンセクションとして誤って認識されると、チャンクが過度に小さくなります。これを回避するには、検索インデックスを作成するときに次の設定を使用します。
- Max Token (最大トークン): 隣接する小さなセクションをより大きなチャンクに結合することで、一貫性を犠牲にすることなくチャンクサイズを最適化します。「How the Max Token Setting Affects Chunking (最大トークン設定によるチャンクへの影響)」を参照してください。
- 重複トークン: 1 つのセクションから複数のチャンクが作成された場合にのみ使用されます。各チャンクの末尾から次のチャンクの先頭までに追加するトークン数を指定します。これにより、連続するチャンク間でコンテキストの重複が発生し、スムーズな移行と検索や取得などのタスクのパフォーマンスが向上します。
組み合わせたコンテンツが設定されたトークン制限を超えない場合は、複数の段落を 1 つのチャンクにグループ化できます。
トークンの制限に達すると、チャンクロジックによって文や段落の途中で分割されず、区切りがなくなります。代わりに、段落の末尾まで拡張され、チャンク全体でセマンティックと構造の整合性が維持されます。
たとえば、このテキストはタイトルと後続のセクションヘッダーに基づいてセクションに分割されます。

結果のチャンクデータモデルオブジェクトの例には、次のレコードが含まれます。
| チャンク シーケンス番号 | チャンク | DaTAsource オブジェクトのチャンク | データソース |
|---|---|---|---|
| 1 | Retrievers A retriever returns relevant data from the vector database
to augment a prompt. By augmenting prompts with accurate, current, and pertinent
information, retrievers improve the value and relevance of LLM responses for
users. . . |
DataSourceObject__c |
DataSource__c |
| 2 | Default and Custom Retrievers When a search index is created in Data
Cloud, a default retriever is created automatically. You can't customize a default
retriever. However, in Einstein Studio, you can create and customize retrievers
for search indexes. |
DataSourceObject__c |
DataSource__c |
| 3 | Dynamic Retrievers Some standard templates contain dynamic retrievers.
A dynamic retriever is a placeholder for a retriever specified at runtime
depending on the needs of the prompt template. To test a dynamic retriever, enter
the retriever’s API name, which you can find in Einstein Studio. |
DataSourceObject__c |
DataSource__c |
Data 360 の高度なビルダーで検索インデックス設定を作成する場合、セクション対応チャンクが HTML ファイルと PDF ファイルのデフォルトのチャンク戦略になります。
セマンティックベースのパッセージ抽出
セマンティックベースの通路の抽出では、HTML タグに固有のセマンティックな意味を使用して文書を通路に分割します。これらの HTML 要素はチャンクの論理境界とみなされます。
- ヘッダーレベル 1 ~ 6 の
<h1-h6> - テーマ別休憩
<hr> - 太字
<b>– タグ付きテキストが単独行にある場合や、font_weightが 700 以上に設定されている段落やfont_weightがboldに設定されている段落のテキストで使用されている場合に使用します。 - 強い
<strong>— タグ付きテキストが 1 行にある場合、またはfont_weightが 700 以上に設定されている段落やfont_weightが太字に設定されている段落のテキストで使用されている場合に使用します。 - 段落
<p>— タグ付きテキストが単独の行にある場合に使用します。 - 改行
<br>— 現在のチャンクがトークン制限を超えた場合に使用されます。
たとえば、このテキストにはいくつかの HTML 要素が含まれています。
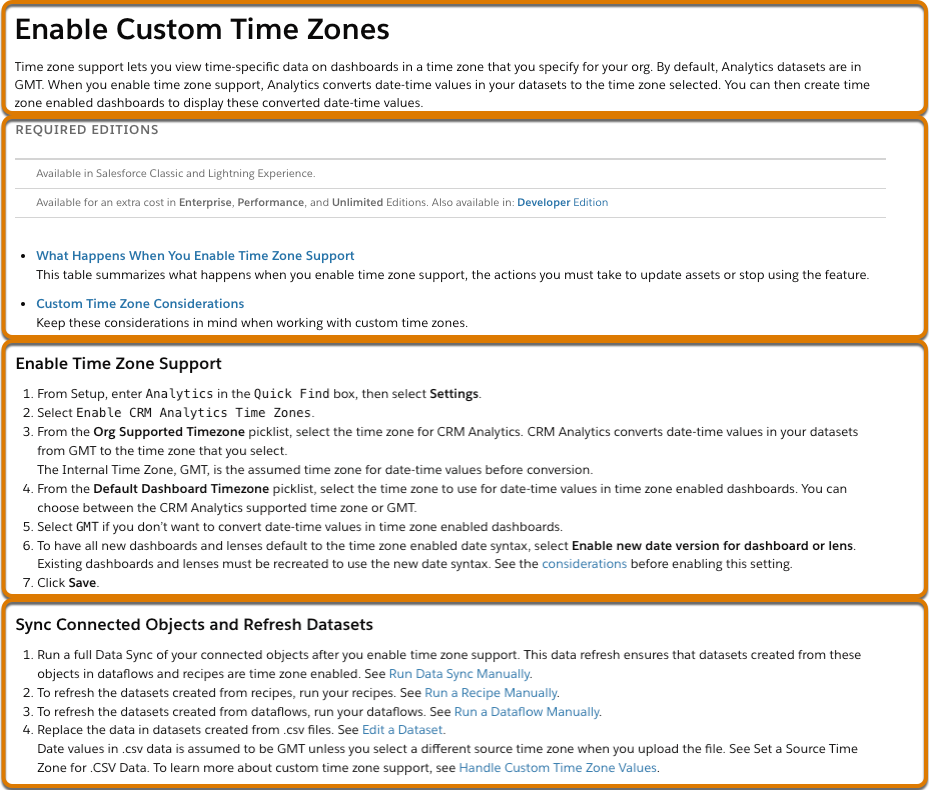
HTML では次のようになります。
<h1>Enable Custom Time Zones</h1>
<p>Time zone support lets you view time-specific data...</p>
<h4>REQUIRED EDITIONS</h4>
<p>Available in Salesforce Classic and Lightning Experience</p>
<p>...</p>
<h2>Enable Time Zone Support</h2>
<ul>...</ul>結果のチャンクデータモデルオブジェクトの例には、次のレコードが含まれます。
| ChunkSequenceNumber | チャンク | データソースオブジェクト | データソース |
|---|---|---|---|
1 |
Enable Custom Time Zones Time zone support lets you view time-specific
data.... |
DataSourceObject__c |
DataSource__c |
2 |
REQUIRED EDITIONS Available in Salesforce Classic... |
DataSourceObject__c |
DataSource__c |
3 |
Enable Time Zone Support From Setup, enter
Analytics... |
DataSourceObject__c |
DataSource__c |
4 |
Sync Connected Objects and Refresh Datasets Run a full Data Sync of
your connected objects... |
DataSourceObject__c |
DataSource__c |
2 つのヘッダータグの間にコンテンツがない場合、それらのタグと後続のコンテンツは 2 つではなく 1 つのチャンクで表示されます。ヘッダー間にコンテンツがない場合、Data 360 は 1 つのチャンクに収まるだけのヘッダータグを組み合わせます。
デフォルトでは、Data 360 では最初にセマンティックベースの方法が使用されますが、結果の通路が長すぎる場合は、ウィンドウベースの通路抽出を使用してさらに処理されます。ウィンドウベースの抽出では、<div>や<p>などのブロックレベル要素、または改行<br>で区切られた未加工テキストを使用して、ドキュメントを通路に分割します。段落に HTML が含まれない場合、集計は文レベルで行われます。
会話ベースのチャンク
会話ベースのチャンクでは、音声ファイルと動画ファイルから文字起こしされたデータをチャンクに分割します。通常、音声が変更されると分割されます。
文字起こし中に複数の話者が存在する場合、各チャンクは個々の話者の話を表します。
トランスクリプトの最初の数行を次に示します。
"Hello? Hi Alex, it's Sam from Bullseye. I didn't hear from you yesterday, so I wanted to check in. Hi Sam, sorry about that."結果のチャンクデータモデルオブジェクトの一部に次のレコードが含まれます。
| ChunkSequenceNumber | チャンク | 開始タイムスタンプ | 終了タイムスタンプ | スピーカー |
|---|---|---|---|---|
1
|
Hello?
|
1.051
|
1.253
|
SPEAKER_00
|
2
|
Hi Alex, it 's Sam from Bullseye. I didn't hear from you yesterday, so I
wanted to check in.
|
3.203
|
8.418
|
SPEAKER_01
|
3
|
Hi Sam, sorry about that.
|
10.263
|
11.546
|
SPEAKER_00
|
項目チャンクの先頭へ
DMO または UDMO から生成されたチャンクのコンテキストを提供するためにメタデータを追加する必要がある場合、チャンクに項目を追加します。たとえば、ナレッジ記事の Description 項目は、プロンプトベースの取得に最適なチャンク サイズを超える可能性があります。チャンクの先頭に Title 項目を追加することで、プロンプト結果により多くのコンテキストを提供できます。
次の表に、便利なメタデータ項目の例を示します。
| タイプ | メタデータ項目の例 |
|---|---|
| DMO (Knowledge記事) |
|
| UDMO (外部 Blob ストアコネクタ) | ファイルパス |
| UDMO (Web クローラーまたはサイトマップコネクタ) |
|
ベクトル検索またはハイブリッド検索の検索インデックスの高度な設定で、DMO または UDMO からチャンクの先頭に追加する項目を設定します。
チャンクの最大トークン制限は 512 であるため、先頭に追加する項目の値は必ずその制限内に収まるようにします。先頭に追加される項目の長さが 512 トークンを超える場合、Data 360 は先頭に追加される項目をスキップします。