
詳細情報:
予測データ用語
Einstein 予測ビルダーを使用する場合、データのセットについて使用する用語を理解しておくと役立ちます。
予測を構築するうえでの最初のステップは、予測する項目を含むオブジェクトを選択することです。そのオブジェクトのレコードのセットが全体のデータセットです。たとえば、見込み客がイベントに参加する可能性を予測するとします。したがって、予測はリードオブジェクトに基づきます。544 件のリードがあります。それがデータセットです。
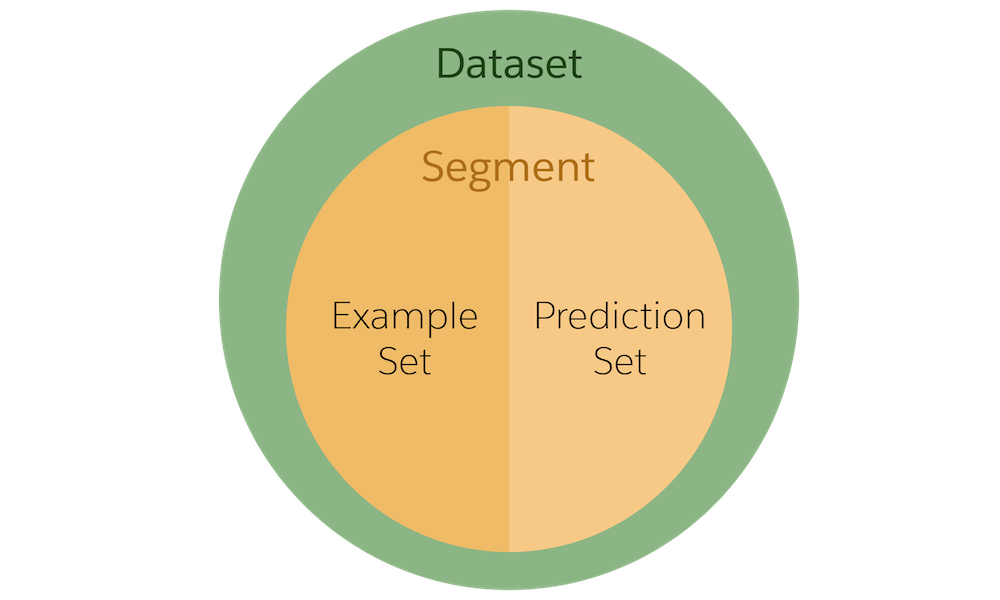
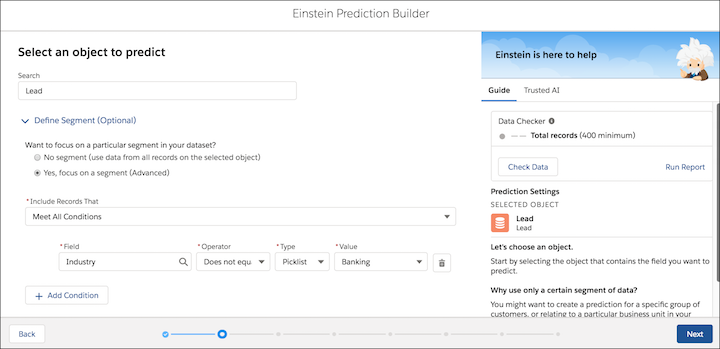
オブジェクトを選択したら、データの区分に予測の焦点を絞るオプションがあります。条件ロジックを使用してデータセットを絞り込み、そのデータのサブセットを作成します。たとえば、銀行以外の業種からのリードのみに関心があるとします。区分には 503 件のリードがあります。
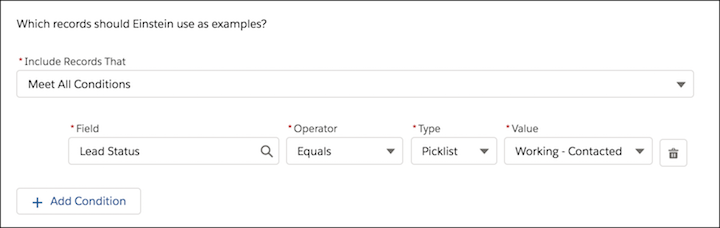
予測を構築するためのサンプルとして区分、または区分に焦点を絞らない場合はデータセット全体のどのレコードを使用するのかを指定します。次のレコードはサンプルセットです。Einstein では、これらのレコードからパターンを特定し、他のレコードの予測が作成されます。サンプルセットには、前回のイベントに参加した人または参加しなかった人のリードを含む必要があります。そのために、処理中のリードのみが含まれるように条件を設定します。新規リードではなく、処理中のリードを使用することで、以前のイベントの参加に関するさまざまな値がサンプルセットに含まれる可能性が高くなります。
Einstein で値が予測されるレコードのセットを予測セットといいます。予測セットは、Einstein が予測結果 (スコア) を提供する区分 (区分を使用しない場合はデータセット) 内のすべてのレコードで構成されます。デフォルトでは、サンプルセットに存在しないレコードにスコアを付けます。この場合は、新規リードを意味します。

予測を構築するときにデータチェッカーは、区分、サンプルセット、予測セットに予測の構築に十分なレコードがあることを確認します。